
この記事では2020年2月にリリースされた、DeepFaceLabの最新版、DeepFaceLab 2.0を使ったDeepfake動画の作り方を解説していきます。
DeepFaceLab1.0と2.0の違い
DeepFaceLab 2.0は、以前のバージョンのDeepFaceLab 1.0よりも、より高速かつ高品質に処理できるようなりました。学習モードが「SAEHD」と「Quick96」の2種類のみになり、オプションの項目が増え、 機能も増えましたが基本的な使用方法は、DeepFaceLab1.0と変わりません。
ただし、両バージョンに互換性がありませんから、DeepFaceLab 1.0で作ったモデルを、DeepFaceLab 2.0で使用することはできません。
また、DeepFaceLab 2.0からは、NVIDIAのビデオカード(GPU)しかサポートされません。AMDのビデオカードをお使いの方はDeepFaceLab 1.0をお使いください。
DeepFaceLab 2.0を使うのに必要なモノ
前述したように、DeepFaceLab 2.0からはNVIDIAのビデオカード(GTX 10シリーズ、GTX 16シリーズ、RTXシリーズ)しかサポートされません。
そのなかでも、基本的にはVRAMが6GB以上のものをおすすめします。VRAMが6GB未満だと、処理能力不足です。
後で詳しく述べますが、ローエンドモデル用(VRAM 4GB以上推奨)の学習モード「Quick96」もありますが、解像度が低いため、基本的には最低でもVRAMは6GB以上必要と考えてください。
DeepFaceLab 2.0のダウンロード
DeepFaceLab 2.0は下記のGoogleドライブ、もしくはGithubからダウンロードできます。
「DeepFaceLab_NVIDIA_build_02_28_2020.exe」というような名前のファイルをダウンロードしてください、buildの後はリリースされた日付になります。
DeepFaceLabのbuildは、バグの修正や機能の追加などで、こまめにアップデートされます。ただし、必ずしも最新のbuildを使うことが良いとも限りませんので、ご注意ください。
今回の例では「DeepFaceLab_NVIDIA_build_02_28_2020.exe」を使用しています。
ダウンロードしたファイルの解凍
ダウンロードしたらファイルを解凍します、解凍場所はデスクトップでもCドライブ直下でも、どこでも構いません。
解凍場所を指定し、「Extract」をクリックする。
解凍が終わるのを待ちます、1分程度で終わります。
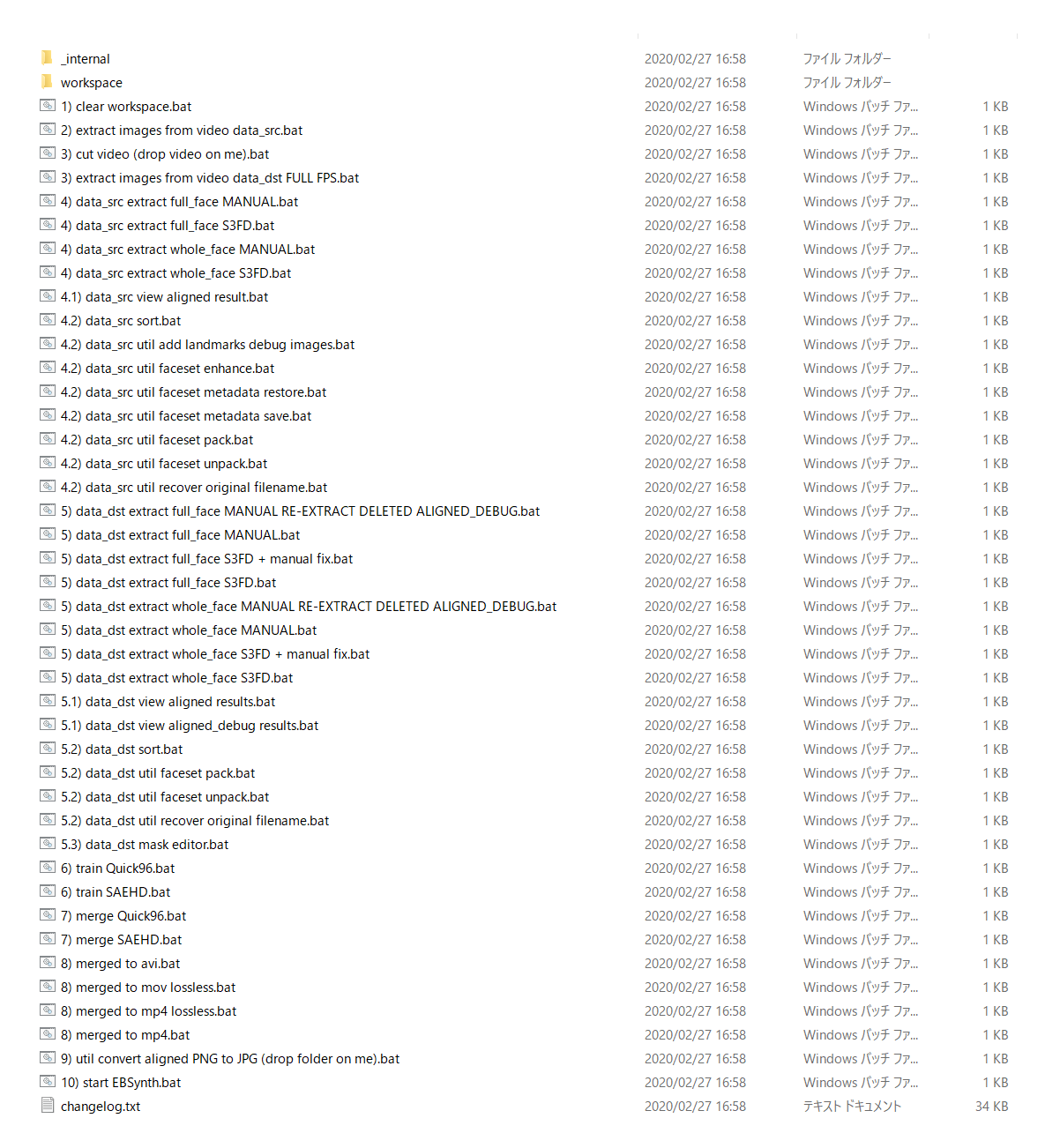
解凍されたフォルダ名は「DeepFaceLab_NVIDIA」となっています。これは自由に変更したりしても問題ありません。

解凍したフォルダを開いてみましょう。
DeepFaceLab 1.0のときと同様、バッチファイルがたくさん入っています。
DeepFaceLabはインストールして使うソフトウェアのようなものではなく、必要なバッチファイルを順に実行するようにして使用します。一見「ややこしそう」ですが、素材を準備して、手順通りに必要なバッチファイル実行していくだけですから簡単です。
動画制作の手順
動画制作の手順は下記の通りです。基本的にDeepFaceLab 1.0と同じ流れで処理していきます。
1.素材を準備する
素材となる動画を準備します。素材は何でも構いませんが、まずは1~3分程度の短いもので試してみるのが良いかと思います。動画が長くなればなるほど、すべての処理で時間がかかります。
素材は顔を移植する側とされる側の2種類が必要です。
data_src – 「別の人物の体に移植する顔となる素材」
data_dst – 「別の人物の顔を移植される素材」
例えば「ニコラス・ケイジの顔を、ドナルド・トランプに移植する」場合は、ニコラス・ケイジの動画がdata_src、ドナルド・トランプの動画がdata_dstとなります。
用意した素材は、それぞれ上記の例のようにdata_srcとdata_dstに名前を変更し、workspaceフォルダに入れておきます。
最初からサンプルの動画が入ってますので、サンプルは消しましょう。
素材動画の注意点
使用する素材にはいくつか注意が必要です。場合によっては事前に動画編集ソフトで、編集する必要があります。
・動画に複数の人物の顔が映っていないこと
この後の工程で人物の顔部分のみを画像で書き出しますが、動画内のすべての顔と認識されるものが書き出されますので、動画には一人の人物の顔しか映らないようにしましょう。(複数人の顔が映る場合は、不要な人物の顔部分を塗りつぶす等の処理が必要です)
・人物の顔が十分なサイズで写っていること
素材となる動画(特にdata_src)は人物の顔がある程度の大きく映っている必要があります。具体的には顔部分の画像の書き出しは256×256ピクセルもしくは512×512ピクセルの正方形なので、動画上の人物の顔のサイズがこの程度のサイズで写っていることが望ましいでしょう。
2.素材動画を全フレーム画像で書き出し
2) extract images from video data_src.bat を実行して、data_srcの動画を画像で書き出します。data_srcは顔を移植する側、つまり画像は学習にしか使用しないないので、必ずしも全フレーム書き出す必要はありません。
FPS選択時に何も打たずにEnterを押すと全フレームが書き出されます。フレームレートを指定する場合は数値を入力します。
素材が短い場合は全フレーム書き出したほうが良いでしょう。
書き出す画像形式は、劣化のないpngをおすすめします。
- [0] Enter FPS ( ?:help ) :何も打たずEnterで全フレーム書き出し
- 0
- [png] Output image format ( png/jpg ?:help ) :何も打たずEnter
- png
3) extract images from video data_dst FULL FPS.bat を実行して、data_dstの動画を全フレーム画像で書き出します。こちらは顔を移植される側なので、最後に顔を移植して動画にする際に全フレーム必要になるので、自動的に全フレーム書き出しとなります。
こちらも劣化のないpng形式で書き出すことをおすすめします。
- [png] Output image format ( png/jpg ?:help ) :何も打たずEnter
- png
書き出された画像はそれぞれ「workspace」フォルダ内のフォルダ「data_src」「data_dst」に保存されます。
3.顔部分のみを抽出
前の工程で書き出した画像から、さらに顔部分のみを抽出し画像で書き出します。
「4) data_src extract full_face S3FD.bat」を実行しdata_srcの画像から顔部分のみを抽出します。
「5) data_dst extract full_face S3FD.bat」を実行しdata_dstの画像から顔部分のみを抽出します。
書き出された画像は、それぞれ「data_src」「data_dst」のフォルダ内の「aligned」というフォルダに書き出されます。
NVIDIAドライバダウンロード https://www.nvidia.co.jp/Download/index.aspx
4.誤検出された画像を削除
前工程での顔部分のみの抽出ですが、完ぺきではないので、何かしらの誤検出があります。これらが学習時に入っていると悪影響を及ぼすので、削除する必要があります。よくあるのは「耳」や「グーにした状態の手」、「家具の模様」など思わぬものが顔として認識されています。
誤検出した画像を膨大な画像の中から目視で探し出すのはとても苦労します。そこで誤検出した画像を発見しやすいように、「4.2) data_src sort.bat」を使って並べ替えてから、目視で削除していきます。
「4.2) data_src sort.bat」を実行すると、どのように並べ替えるかを選択できます。おすすめは[3] histogram similarityです。ヒストグラムの近い画像順に並べ替えてくれるので、実行すると似ている画像が並ぶようになります。これにより誤検出した画像が発見しやすくなります。
並べ替えが終わったら、alignedフォルダを開き誤検出された画像を削除します。
- Running sort tool.
- Choose sorting method:
- [0] blur
- [1] face yaw direction
- [2] face pitch direction
- [3] histogram similarity
- [4] histogram dissimilarity
- [5] brightness
- [6] hue
- [7] amount of black pixels
- [8] original filename
- [9] one face in image
- [10] absolute pixel difference
- [11] best faces
- [3] : 3
- 3
data_dstも同様に「5.2) data_dst sort.bat」を実行し、並べ替えた後、誤検出された顔画像を削除します、
5.学習させる(train)
いよいよ学習をさせていきます。ここはDeepFaceLab 1.0から大きく変わった点のひとつです。DeepFaceLab 2.0では現在2種類の学習方法があります。どちらか一方のみを使用します。
6) train SAEHD.bat
VRAM 6GB以上のハイエンドGPU用。「build_02_23_2020」以前は最大256×256ピクセル、 「build_02_28_2020」 以降は最大512×512ピクセルの解像度で学習させることができます。フルHD(1080×1920ピクセル)やHD(1280×720ピクセル)の動画を素材に使う場合は、このモードをおすすめします。
6) train Quick96.bat
VRAM 4GB以上のローエンドGPU用。軽量版の学習モード。一応、それなりに学習させることはできますが、解像度が96×96ピクセルのため、いくら学習させても解像度不足は補うことはできません。SD画質・480p(480×720ピクセル)程度の動画であれば、このモードでも良いかもしれません。
今回は「6) train SAEHD.bat」を使用します。実行するとオプションを尋ねられるので、入力していきます。
(「6) train Quick96.bat」でも手順は同じです、オプションがほとんどないだけです。)
train時のオプション
モデル名の入力
DeepFaceLab 2.0から、学習するモデルに名前をつけることが可能になりました。これにより同じDeepFaceLabのフォルダ内に複数のモデルを作成・学習することができるようになりました。
- Running trainer.
- [new] No saved models found. Enter a name of a new model : モデル名の入力してEnter
一度、保存したモデルの学習を再開する場合も同様にモデル名をここで入力します。
GPUの選択
使用するGPUを選択します。
- Choose one or several GPU idxs (separated by comma).
- [CPU] : CPU
- [0] : GeForce GTX 1080 Ti
- [0] Which GPU indexes to choose? : 0
- 0
Write preview history ( y/n ?:help ) :
「y」にすると、10回の反復(学習)おきにプレビュー画面を保存してくれます。保存場所は「workspace > model > [モデル名]_SAEHD_history」です。
基本的には不要なので「n」にします。
[0] Target iteration :
何回まで反復(学習)するかを入力できます。基本的に無制限に学習させるので「0」(無効)にします。手動で学習を終了させるまで、無制限に学習を続けます。
Flip faces randomly ( y/n ?:help ) :
「y」(有効)にすると、元の画像に加えて、左右反転させて学習させることができます。
例えばdata_dstに、右を向いているシーンがあったとします。しかし、data_srcには右を向いているシーンがない、もしくは少ない場合に、左を向いている画像を左右反転させることによって、これを補って学習することができます。
ただし、ランダムで左右反転し学習させるため、顔のほくろやキズなども顔の両側に表れることになります。また、人の顔は必ずしもピッタリ左右対称という訳ではないため、data_srcに顔が似ない可能性もあります。
必要に応じて選択してください。デフォルトは「n」(無効)です。
[8] Batch_size ( ?:help ) :
バッチサイズを指定します。バッチサイズがある程度大きいと学習の進度が早くなります(LOSS値が早く低下し、ブレも少なくなる)。ただし、バッチサイズが大きいほどVRAMの容量を圧迫するため、バッチサイズが大き過ぎるとエラーでtrain(学習)が始まらないこともあります。
バッチサイズは学習時の解像度や他の設定との兼ね合いもあるので、参考例を後で示します。
[128] Resolution ( 64-512 ?:help ) :
学習時の解像度を指定できます。解像度が高ければ高いほど、ボヤけの少ない、より高精細なモデルをつくることができます。しかし、これもバッチサイズと同様に大きければ大きいほどVRAMを圧迫するため、大きいとエラーでtrain(学習)が始まらないこともあります。
[f]Face type ( h/mf/f/wf ?:help ) :
学習するモードを選べます。
- FULL FACE (f):顔全体を学習
- HALF FACE (h):口から眉の間(顔の中心部分)のみを学習
- MID HALF FACE (mf) :HALF FACEよりも30%大きい範囲を学習
- WHOLE FACE (wf):FULL FACEよりもさらに広い範囲(頭や顔の形)まで学習
通常はFULL FACE (f)を使用すると良いと思います。
HALF FACE、MID FACEは、同じ解像度でもFULL FACEに比べ顔の中心部分を高い解像度で学習させることができる利点もあります。

AE architecture ( dfhd/liaehd/df/liae ?:help ) :
学習アーキテクチャを選択します。DeepFaceLab 2.0には、DFとLIAEの2種類のアーキテクチャがあります。また、それぞれにおいてパフォーマンスを犠牲にし品質を優先するHDバージョンがあります。
DF
このモードでは、顔の変形は行わないモードです。顔が正面に向いているシーンが多いものに最適なモードです。data_srcに再現するすべての角度の画像が必要なため、横顔などが多いシーンには不向きです。
LIAE
このモードでは、顔の変形を行います。正面の顔はDFに比べ再現性が劣りますが、横顔はLIAEのほうがはるかに上手く処理することができます。

次にオートエンコーダー、エンコーダー、デコーダー、デコーダーマスクの設定ですが、特にデフォルト値から変更する必要もないので、何も打たずにEnterでスキップし、デフォルト値を使用します。開発者も「安定した動作が必要な場合は、デフォルトのままにしてください」としています。
- [256] AutoEncoder dimensions ( 32-1024 ?:help ) :何も打たずにEnter
- 256
- [64] Encoder dimensions ( 16-256 ?:help ) :何も打たずにEnter
- 64
- [64] Decoder dimensions ( 16-256 ?:help ) :何も打たずにEnter
- 64
- [22] Decoder mask dimensions ( 16-256 ?:help ) :何も打たずにEnter
- 22
[n] Learn mask ( y/n ?:help ) :
「y」(有効)にすると、顔の形状の学習を行って、merge(顔を合成する工程)で使用できるマスク(Learn mask)を生成することができます。通常はdata_dstのフレームから顔画像を書き出す工程で生成されるマスク(dst mask)を、mergeで使用しています。dst maskよりもLearn maskのほうが優れていますが、この機能を有効にするとVRAMに大きな負荷がかかる(1回あたりの反復(学習)に時間がかかる)ため、使うとしても学習中のどこかで5000~6000回程度の間だけ有効にすることをオススメします。顔の学習の品質には影響しません。
この機能は何度でも有効・無効にすることができます。
通常は「n」(無効)で良いと思います。dst maskに万が一不満があれば、Leran maskを使ってみると良いかもしれません。
[n] Eyes priority ( y/n ?:help ) :
Deepfakeで合成した顔では、目やその周辺の描写が上手く行かないケースがよくあります。「y」(有効)にすると、これらが改善されます。ただし、目線の方向を正しい方向することを保証する機能ではありません。デフォルトでは「n」(無効)ですが、私自身は「y」(有効)にしています。
[y] Place models and optimizer on GPU ( y/n ?:help ) :
「y」(有効)にすると、GPUのVRAMにほぼすべてのデータを置くため、1回の反復(学習)にかかる時間が大幅に短縮し、train(学習)の速度が速くなります。ただし、バッチサイズが小さくなります。(DeepFaceLab 1.0でも同じ方式)
「n」(無効)にすると、データをメインメモリ(システムRAM)に置くため、VRAMへの負荷が減り、わずかに高いバッチサイズでtrainを実行できたり、より高い解像度(Resolution)でtrainを実行できる可能性があります。ただし1回あたりの反復(学習)にかかる時間が大幅に増大し、train(学習)の速度が遅くなります。
VRAMが6GBで、システムRAMが16GBや32GBある場合(VRAMは少ないけど、システムRAMはたくさんあるよ という場合 )には、「n」(無効)にして、時間を犠牲にし、品質を優先するというのもひとつの方法でしょう。
とはいえ、VRAMにデータを置いて学習しても、数万~20万回と反復(学習)させるには、とてつもない時間がかかりますから、基本的には「y」(有効)にしましょう。デフォルトでも「y」(有効)です。
[n] Use learning rate dropout ( y/n ?:help ) :
この機能は使用するとしても、トレーニングの最終段階(数十万回学習が終わってから)のみで「y」(有効)にしてください。また、「random warp of samples」や「flip faces randomly」の機能と同時に有効にしないでください。モデルがかなりよく学習されてから、「random warp of samples」「flip faces randomly」の機能を無効にした上で、この機能を有効にしてください。モデルがよりシャープになります。モデルが十分に訓練されていない状態で有効にすると、悪影響を及ぼします。
必ずしも使用する必要のある機能ではありません。
デフォルトでは「n」(無効)です。
[y] Enable random warp of samples ( y/n ?:help ) :
モデルを一般化し、基本的な形状、顔の特徴、構造を適切に学習するために使用します。初期段階はこの機能は有効にして学習を行い、学習が進んでいる間は有効にしておきましょう。学習が停滞してきたら(LOSS値が減少しなくなってきたら)、この機能を無効にし学習させることで、顔のより詳細な部分を学習させることができます。ここまで学習させるには数十万回の反復(学習)が必要です。
デフォルトでは「y」(有効)です。
[0.0] GAN power ( 0.0 .. 10.0 ?:help ) :
こちらの機能も十分に訓練がされてから「 random warp of samples 」を無効にした上で、「y」(有効)にするオプションです。より詳細(シャープ)な顔を生成することができます。ただし、data_srcのデータセット(顔画像)の品質に大きく依存するため、必ずしも良い結果が得られるとは限りません。良い結果が得られるかどうかを試すために、低い値から始めることをオススメします。また、この機能を有効にする前にモデルのバックアップを取るようにしましょう。
デフォルトでは「0」(無効)です。




[0.0] Face style power ( 0.0..100.0 ?:help ) :
[0.0] Background style power ( 0.0..100.0 ?:help ) :
学習済みの顔に、data_dstの画像の顔・背景部分のスタイルを適応することで、merge(顔を合成する工程)での、合成の品質・外観が良くなります。しかし、値が大きいと学習したにもかかわらずdata_dstの顔になってしまいます。最大でも10.0を指定し、トレーニング中に1.0から0.1まで下げていくことをオススメします。

要は設定が強いほど、合成した顔がdata_dstの顔っぽくなります。data_dstの目や唇・肌の色や化粧などを引き継ぎたい場合には、有効な機能だと思います。
ただし、この機能はパフォーマンスに大きな影響を与えるため、バッチサイズを小さくするか、「Place models and optimizer on GPU」を無効にする必要があります。また、1回の反復(学習)にかかる時間も増大するため、学習の速度も低下します。
デフォルトでは「n」(無効)です。
Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) :
data_srcの肌の色を、data_dstの肌の色に合わせるための機能です。いくつか種類がありますが、「rct」もしくは「lct」がオススメです。

[n] Enable gradient clipping ( y/n ?:help ) :
DeepFaceLab 2.0の様々な機能を使用することで発生する可能性のある、モデルの崩壊・破損を防ぐための機能です。パフォーマンスへの影響は小さいため、デフォルト値は「n」(無効)ですが、常に「y」(有効)にすることをオススメします。
[n] Enable pretraining mode ( y/n ?:help ) :
ここでは詳しく説明しませんが、トレーニング済みのをモデルを入手し、これを使用する場合に使う機能です。
基本的には「n」(無効)にしておいてください。
これでtrainのオプションの設定は完了です。素材となる画像の読み込みが始まり、無事にtrain(学習)が開始されると、プレビューウィンドウが立ち上がってきます。
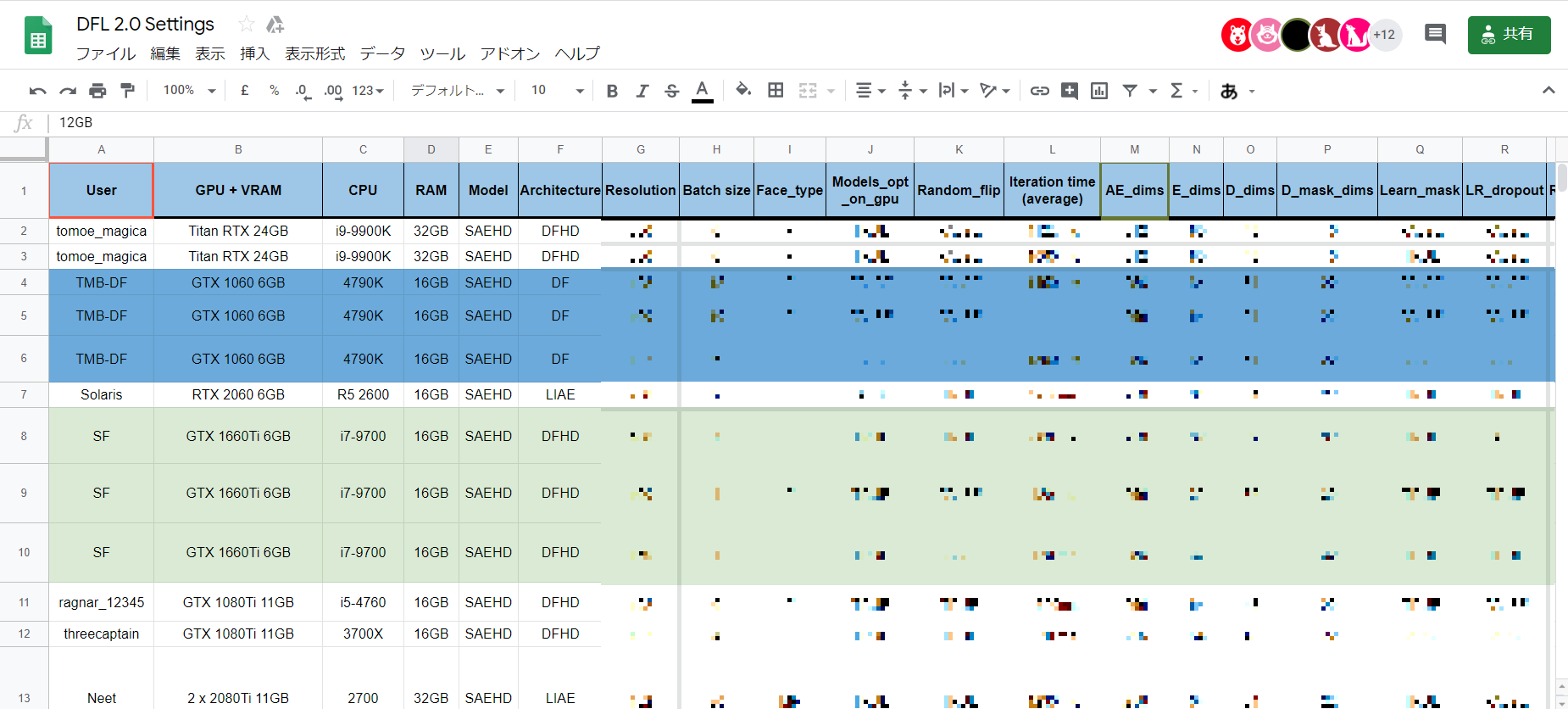
エラーでtrainがはじまらない場合は設定(バッチサイズ・解像度・アーキテクチャー)を見直しましょう。必ず動くという保証はできませんが、設定値の参考例を以下に示します。
| GPU (VRAM容量) | アーキテクチャ | 解像度(Resolution) | バッチサイズ |
| GTX 1650 (4G) | DF | 128 | 6 |
| GTX 1660Ti (6GB) | DFHD | 160 | 7 |
| RTX 2060 (6GB) | DF | 128 | 14 |
| RTX 2060 (6GB) | DFHD | 128 | 8 |
| RTX 2060 S (8GB) | DFHD | 160 | 9 |
| RTX 2070 S (8GB) | DFHD | 128 | 8 |
| GTX 1080Ti (11GB) | DFHD | 192 | 6 |
| Titan RTX (24GB) | DFHD | 256 | 8 |
ちなみにmrdeepfakes.comという海外のフォーラムに、「この設定なら動いたぞ」というのをユーザーが記入しているスプレッドシートへのリンクがあります。
https://mrdeepfakes.com/forums/thread-guide-deepfacelab-2-0-explained-and-tutorials-recommended
ただし、ログインしないとリンクの表示は許されないようなので、ご覧になりたい方は、各自登録して閲覧してみてください。登録しても特にスパムメール等が送られてきたりはしません。
train時のウィンドウの見方
DeepFaceLab 1.0の使い方の記事を書いたときに、質問が多かったtrain時のウィンドウの見方について説明します。trainがはじまると、もともと開かれていた黒いコマンドラインウィンドウに加えて、視覚的に学習状況を把握できるプレビューウィンドウが立ち上がってきます。
コマンドラインウィンドウ
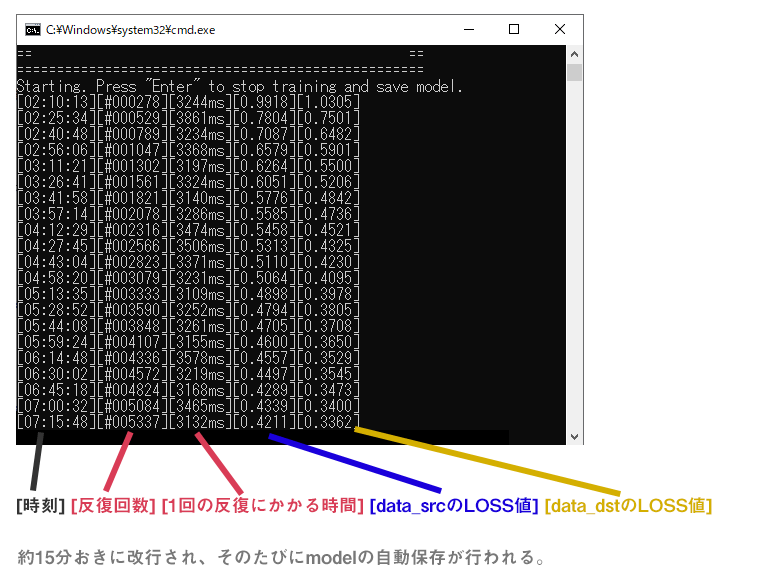
コマンドラインウィンドウには上記の情報が表示されます。
- 反復回数 - 学習回数です。これが5万回ほどいくと、それなりにdata_srcの顔っぽくなってきます。どこが完成というのはありませんが、少なくとも20万回程度は反復させたほうが良いでしょう。(5、6万回に達したところで一旦、動画にしてみるというのも、もちろんOKです。)
- 1回の反復にかかる時間 - そのままですが、これは結構重要です。これで学習の速度が分かります。例えば1回の反復に3000ms(3秒)かかっていたとします。この場合、24時間で28,800回 反復させることができます。これが1000ms(1秒)なら、86,400回 反復させることができます。たかが、2秒の違いですが、何万、何十万回と長時間学習させるため大きな差が出てきます。ですから、反復回数はできるだけ短くしたい訳です。
- LOSS値 - LOSS値は簡単に言うと、この数値が学習の進行度合いを表しています。少なくなればなるほど、学習が進んでいるということになります。時間経過と共にLOSS値が徐々に少なくなっていくのが望ましい(正常)です。LOSS値が安定しない(上昇、低下を繰り返す)場合等は、データセットや学習方法を見直す必要があります。最終段階まで行くと、LOSS値が安定し低下しなくなります。ここまで行けば完成と言って良いでしょう。
プレビューウィンドウ

基本的には画像の通りです。Iterはコマンドラインウィンドウにも表示されている反復回数。青と黄のグラフは、LOSS値をグラフ化したもの。下の画像部分は現在のmodelデータを反映したプレビュー。pキーで更新できます。
モデルデータの保存と学習の再開
このウィンドウを選択した状態でEnterを押すとモデルを保存し、train(学習)を終了します。再開する場合は、再度バッチファイルを実行し、モデル名を入力します。再開時にGPU選択から2秒以内にEnterキーを押すと、設定可能なオプションを再設定することができます。何も押さなければ、前回の設定のままtrain(学習)を再開します。
6.顔を移植した画像を書き出し(merge)
学習したモデルを使って、data_dstの動画の画像に、顔を合成していきます。
trainを終了してから、「7) merge SAEHD.bat」を実行します。
mergeのオプション
[y] Use interactive merger? ( y/n ) :
対話型のコンバーターを使用するか、しないかです。今回は通常のコンバーターを使用するので「n」(通常のコンバーターを使用)にします。
[new] No saved models found. Enter a name of a new model :
どのモデルを使ってmergeするかを、入力します。
[0] Which GPU indexes to choose? :
使用するGPUを選択します。
Choose mode:
(0) original
(1) overlay
(2) hist-match
(3) seamless
(4) seamless-hist-match
(5) raw-rgb
どのモードで合成を行うか選択します。オススメは「(1)overlay」です。
Choose mask mode:
(1) learned
(2) dst
(3) FAN-prd
(4) FAN-dst
(5) FAN-prdFAN-dst (6) learnedFAN-prd*FAN-dst
どのマスクを使って合成するか、選択します。通常はdst maskを使用するので「(2)dst」を選択します。
train時にLearn maskのオプションを有効にしており、合成にLearn maskを使用したい場合は「(1) learned」を選択します。
[0] Choose erode mask modifier ( -400..400 ) :
マスクの範囲の大きさを調整できます。基本的に元のままの「0」で良いでしょう。
[0] Choose blur mask modifier ( 0..400 ) :
合成部分の輪郭のぼかしを調整します。デフォルトでは「0」になっていますが、100程度ぼかしをかけたほうが自然に仕上がります。ここは仕上がりを確認しつつ調整してください。
[0] Choose motion blur power ( 0..100 ) :
動体ブレの度合いを調整します。ただし、data_dstの顔画像が同一人物で連続になっている必要があります。例え同じ人物しか映っていなくても、顔画像の画像のファイルの中に 「090890_1.jpg」のような「 _1 」付いている画像が1枚でもできてしまっていると、この機能は使用できません。(同一の人物と認識されていないため)
基本的には「0」(無効)で良いです。
[0] Choose output face scale modifier ( -50..50 ) :
合成する顔の大きさを調整できます。基本は「0」で良いでしょう。
大きくする場合は値を-マイナス、小さくする場合は+にします。
Color transfer to predicted face ( rct/lct/mkl/mkl-m/idt/idt-m/sot-m/mix-m ) :
data_dstとの肌の色を合わせるための機能です。train時と同様「rct」か「lct」がおすすめです。
Choose sharpen mode:
(0) None
(1) box
(2) gaussian
ボックスまたはガウス法のシャープをかけることができます。基本的に「(0)None」で問題ありませんが、必要に応じて使用してください。
[0] Choose super resolution power ( 0..100 ?:help ) :
歯、目などの領域にさらに定義を追加し、学習した顔の詳細/テクスチャを強化できます。通常「0」(無効)で問題ありませんが、必要に応じて適応してください。
[0] Choose image degrade by denoise power ( 0..500 ) :
元のフレーム (data_dst) の外観にノイズ除去をかけることができます。基本的には「0」(無効)で良いですが、data_dstにノイズが多い場合などはこの機能を使用してみてください。
[0] Choose image degrade by bicubic rescale power ( 0..100 ) :
元のフレーム(data_dst)の外観をバイキュービック法を用いてぼかすことができます。例えばdata_dstの画像が高解像過ぎて、合成した顔と違和感がある場合に、顔以外の全体をぼかすことによってこれを軽減できます。通常は「0」(無効)で良いですが、必要に応じて使用してください。
[0] Degrade color power of final image ( 0..100 ) :
通常は「n」(無効)で良いです。数値を上げるほど色の濃淡が弱くなり、ビンテージっぽくなります。色が鮮やかになる訳ではありません。

オプションを選択し終えると、顔を合成したフレームが「workspace > data_dst > merged」に書き出されます。
バッチを途中で中止する場合は「Ctrl + C」で、バッチを中止できます。
7.書き出した画像を動画にする
あとはこれまでの工程で書き出した画像をつなげて動画にするだけです。
8) merged to mp4.bat を実行します。オプションはEnterでスキップして構いません。
動画は「workspace」フォルダ内にresult.mp4という名前で出力されます。
さいごに
これで一通りDeepFaceLab 2.0 を使って動画を制作することができると思います。私もこの手の専門家ではないので、前回の記事と同様に。、うまくいかないところや、間違っているところがありましたら、指摘していただけると幸いです。
今回も質問・コメントなどもありましたら、お気軽にどうぞ。私の答えられる範囲で回答させていただきます。
Twitterのアカウントも作りましたので、そちらで質問していただいても構いません。


ご丁寧な解説ありがとうございます。
ソフトの使い方についてではないのですが、合成される側の動画(data_dst .mp4 )に複数人の顔が表示されている場合は、どうすればよいでしょうか?
以前にもコメントいただいていたようで、ご返信できず申し訳ないです。
一度、試したことがあるのですがdata_dstに、人物A、人物Bのふたりの人物が映っていたとします。
「5) data_dst extract full_face S3FD.bat」を実行すると、当然 両方の人物の顔画像が切り出されます。
次に、「4.2) data_src sort.bat」を実行し[3] histogram similarityで並べ替えます。
ここで誤検出した画像に加えて、人物Bの顔画像も一緒にすべて削除していきます。
これでtrainさせると、data_srcの人物とdata_dstの人物Aで学習させることができます。
このモデルを使って、merge(顔画像を合成)すると、どういう仕組みなのか上手く人物Aのみに顔画像が合成されます。
顔画像はすべて、data_dstどのコマのどこから切り出したものなのか記録していて、data_dst > aligned 内で削除されたところについては、
mergeしないように処理しているんだと思います。
ご丁寧な説明ありがとうございました。非常によくわかりました。
DFL 2.0のデフォルト値
res 128
ae_dims 256
e_dims 64
d_dims 48(dfhd以外は64)
res(解像度)を変えなければとりあえずは特に変更しなくていいです
公式ガイドでは
解像度を上げた場合は
全体をバランス良く上げるようにと書かれています
基本はoverlay rctですが
srcの顔色がバラバラの場合、overlay rctで肌色が合わない場合があります
overlay rctで肌色が合わない場合は、overlay idt-mで肌色が合う場合も多いです
それでも合わない場合は、seamless idt-mで肌色が合う場合も多いです
rctで合わない場合のみidt-m。overlayで合わない場合のみseamless
seamlessだとsrcとdstの相性の影響が出やすいです
似るペアもありますが、overlayほど似ないペアもあります
丁寧な解説ありがとうございます!なんとか、自分の満足行くクオリティにしあげられました!1つ作って思ったのですが、モデルの使い回しはできないんでしょうか?同じdstでsrcだけ別の動画と交換(もしくは逆)する場合、1から学習をやりなおさなければならないんでしょうか?
基本的には同じ人物同士であったとしても、別途学習させる必要があります。
すみません、おかげさまで、うまくtrainingを始めることができました!
質問なのですが、10万回ぐらい学習させた時点で
・素材に壊れた画像を発見した(「data_dst」や「data_src」から画像を削除したい)
・足りなかった素材を追加投入したい(「data_src」に画像を追加したい)
場合、こちらは途中から追加/削除できるのでしょうか?
それとも、最初からすべてやり直すしかないのでしょうか?
画像を足したり、増やしたりして学習させても動けば問題ないと思います。
ただし、data_dstについては、削除すると、削除した顔画像のコマは合成が行われません。
質問失礼します。複数の動画から素材を抽出する場合、一つ目の動画から抽出した画像をコピーしたうえで二つ目以降の動画から抽出をし、最後ににコピーしておいた画像をファイルに張り付ければよろしいのでしょうか?
「複数の動画から素材を抽出する場合」この場合の素材というはdata_srcに使用する素材という認識で良いですかね。
その場合、動画ごとに、フレーム書き出し、顔画像書き出しを行って、trainさせるときに同じ、data_src > aligned のフォルダに混ぜてしまえば問題ありません。
ただし、顔画像のファイル名が連番のままだとファイル名が被ってしまうので、混ぜる前に名前を変えておきましょう。
具体的にはWindowsなら、フォルダ内の画像を全選択し、右クリック > 名前の変更で、名前を一括で変更できます。
なお、data_src > aligned 内の顔画像は、連番でなくとも問題なくtrainできます。
質問失礼致します。
顔を書き出した後なのですが、一枚の顔画像に手なども入り込んでる場合は画像を編集して手などを消した方が良いでしょうか?
なるべく顔だけの方が良いですか?
顔画像が入っているalignedフォルダ内に誤検出された画像がある場合は、train前にその顔画像を削除しておけば、trainに影響はありません。
ご回答有難うございます。
度々すいませんが、顔として認識された画像で顔の口元にマイク等が被っている様な顔画像も消去した方がよろしいでしょうか?
消したほうが良いと思います。
ご返答有難う御座いました。
質問失礼いたします。
まだ2.の段階なのですがつまずいていて、素材動画をworkspaceのdata_srcとdstに入れたのですがextract images from video data_src.batをダブルクリックすると「/!¥ input_file not found.
Done.続行するには何かキーを押してください…」と出てしまい、右クリックし管理者として実行(A)を選択しデバイス変更許可を「はい」にすると「指定されたパスが見つかりません。’ ” ” ‘ は、内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチファイルとして認識されていません。続行するには何かキーを押してください」と出てしまいます。パソコン初心者なのでご指導お願い致します。
NitroN50-600-N78V/G66TA Corei7 8GB 256G SSD+1T HDD GeForceGTX1660Ti Windows10を使用しています
「素材動画をworkspaceのdata_srcとdstに入れたのですが」とありますが、動画の入れる場所を間違えていませんか。
素材となる動画「data_src.mp4」「data_dst.mp4」は、フォルダ「data_src」「data_dst」には入れません。
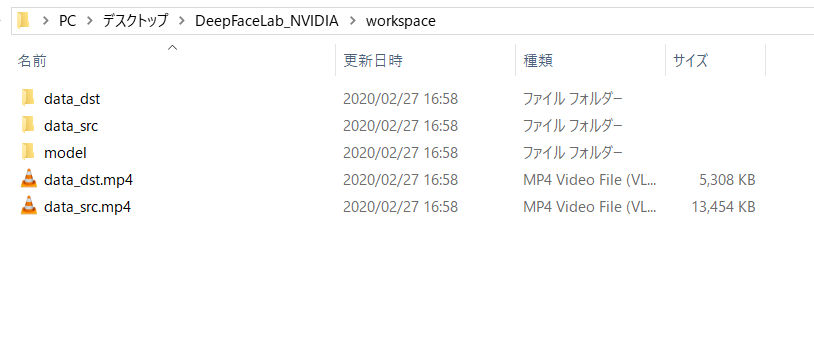
素材動画を置く場所は、フォルダ「workspace」内です。
記事内にもworkspaceフォルダ内の画像を掲載していますが、正しく配置していればworkspaceフォルダ内は下記のようになります。
【workspaceフォルダ内】
📁data_dst
📁data_src
📁model
🎥data_dst.mp4
🎥data_src.mp4
質問です
data_dstのalignedに書きだされた素材なんですが直線または斜めに黒い線が入っていたり腕や髪の毛で片目しか映っていない画像は消したほうがいいんでしょうか。
また、aligned_debugというフォルダーは何をしているんでしょうか?こちらは弄らなくても問題ないのでしょうか
お忙しい所申し訳ないですがお時間あるときに解答宜しくお願いいたします
>data_dstのalignedに書きだされた素材なんですが直線または斜めに黒い線が入っていたり腕や髪の毛で片目しか映っていない画像は消したほうがいいんでしょうか。
学習の際には入ってないほうが良いので、削除するか別の場所に移動させておくのが良いかと思います。
削除した場合はmerge時にその部分は合成が行われません。移動させた場合、merge時に元のdata_dst > aligned に戻しておけば、その部分も合成してくれます。
aligned_debugはどのように顔検出したのかの結果が記録されているものになります。
触る必要は特にないですが、削除はしないようにしましょう。
こんにちわ 教えてください。
①DeepFaceLab 2.0を使用していてDstの顔幅よりSrcの顔幅が小さい時に
動画にすると、顔の幅が違う分だけ、顔の外に透明になっている
部分が出来るのですが、そのような透明部分が出来ないような
方法はあるのでしょうか?
②あと、Dst動画によってtrain時のプレビューでは普通だと思うのですが
動画にしてみると何か絵で書いた様な?感じになる時は解決方法はありますか?
(いつもではなく、Dstによっては自然になる場合もあります)
質問とは関係無いのかも知れませんが、たしかどこかにDstの顔に障害物がある場合に
目的のSrcでtrainする前に、DstのalignedをコピーしてSrcのalignedとしても使用し
て同じaligned同士(Dstのaligned)でtrainして、mergeの時にFan-dstを選択すれば
マスクとか面倒な事をしなくても障害物を認識出来ると書いてあったので
それを選択してます。
ちなみに、前はDstやSrcを変えるたびにtrainを最初からやったりしてましたが
今はDstやSrcを変えても同じmodelファイル?を使いまわして200万回超えてます。
よろしくお願いいたします。
まず1点目ですが、data_dstの人物より、data_srcの人物の顔が小さい場合はmergeの際に「Choose output face scale modifier」のオプションで合成する顔の大きさを調整できます。
デフォルトでは0ですが、確か-(マイナス)方向にすると顔が大きくなります。(マニュアルの画像だと+方向に増やすと大きくなるはずですが、逆になってるようです)
値+-1を変えるだけで、けっこう大きさが変わるので、何度かやってみて微調整してください。
ただし、dstとsrcの人物の顔のつくり(骨格など)が違うと、大きさを調整しても不自然になることが多いです。
2点目については、何が原因か断定はできませんが、srcの素材の品質が悪いか、srcの素材に必要な角度の画像が含まれていない可能性があると思います。
返事が遅くなってすみません。
返信ありがとうございました。
いつも参考にさせて頂いてます。現在CUDA10.1がインストールされているのですが、9.2を再インストールしないと機能しないでしょうか?よろしくお願いします。
実際に試したわけではないので断言はできませんが、DeepFaceLabのフォルダ内にはCUDA9.2も入っており、CUDAをインストールしていないマシンでも動作するようになっています。
このことからCUDAはDeepFaceLabのフォルダ内のものを参照していると思いますので、マシンにインストールされているCUDAのバージョンが10.1でも問題なく動作するかと思います。
質問失礼いたします
mergeをする際に
No frames to merge input_dir
の表示が出て出来ません
原因をお教えいただけますでしょうか
data_dstもしくはdata_src内の必要なファイルを、別の場所に移動してしまっていたり、消してしまったりしていませんか。
すみません
解決しました
わかりやすい解説をありがとうございます。初めてですがDeepFaceLab 2.0を使用して、現在trainをさせている最中です。
ところで、data_srcの素材の「適正尺(長さ)」などはあるのでしょうか?今回は、その人物だけを抽出した素材を全部で10分程度用意したのですが、どの長さを用意したらよいのか迷います。
誤差が少なく、なるべく正確に学習させるための「素材の精度」と「素材の長さ」の関係はどうなっているのでしょうか。
data_srcの動画が長ければ、精度が上がるとは一概には言えません。
(例えば、10分の動画で正面からのカットしかなければ、正面は上手く合成できますが、それ以外の角度ではぼやけたり、顔の形状が破綻したりします)
長さよりも、その人物の顔を様々な角度から映し、表情も色んな表情で写っていて、かつ十分な解像度がある素材がベストです。
確かにある程度の長さは必要になってきますので、短すぎると角度や表情が十分でないので、精度は落ちると思います。
短くて3~5分程度、長いもので20分程度といったところでしょうか。
ご回答ありがとうございました。
いただいたアドバイスの通り「その人物の顔を様々な角度から映し、表情も色んな表情で写っていて、かつ十分な解像度がある素材」を用意しなおして何度か作り直している最中です。
ついでにAE architectureの設定もDFHDからLIAE(当方の環境でLIAEHDでは動かず)に変更したところ、処理速度も上がって再現性も良くなっています。
↑追記。動作したときの設定です。ご参考となれば幸いです。
GPU (VRAM容量)=GeForce GTX 1060(6GB)
動作確認設定①
アーキテクチャ=LIAE/face type=mf/Resolution=160/Batch=2
動作確認設定②
アーキテクチャ=DFHD/face type=f/Resolution=160/Batch=2
質問ですが
「data_src.mp4」の人は色白「data_dst.mp4」の人は普通の肌色でresolutionは256
フェイスタイプはmf
archiはdf
15万回ほど反復し、
マージをやってみたのですが
顔半分が白く、半分が肌色になり
試行錯誤しても上手くいかなく
rctもlctその他でも改善できませんでした。
何かが間違っているのでしょうか?
素材の人物の光の当たり方に違いはありませんか。
例えば、片方は屋外であったり、横から強めの光が当たっていたり。
素材の相性みたいなのもあるので、他でも試してみて上手くいかなかればまたコメントください。
劇的に改善することはないと思いますが、train時のオプション「Color transfer for src faceset ( none/rct/lct/mkl/idt/sot ?:help ) :」では「none」にして学習し、mergeのときにrctもしくはlctでmergeすれば改善するかもしれません。
返信ありがとうございます
なるほどそうなんですね。
ある素材の組み合わせでは上手くいったので
確かに相性みたいなのがありそうと感じました。
しかし何がどうかは自分で答えは出せなかったです。
反復をある程度していたので
Train時にrctを選択したのを「none」にする勇気が無かったです。
教えていただいて納得いきました。
そのnoneの方向でやってみます。
始めまして
かねてより、大変参考にさせていただいております
ありがとうございます
誠にお手数をおかけいたしますが、質問をさせてください
この度、DeepFaceLabをバージョン1から2.0にいたしました所
どうにも解決できない問題に直面いたしました
それは、data_dstフォルダ内に書き出されたシーンの中で、ファイル名6桁以上のカットが動画書き出しを行うと動画の途中に挿入されてしまうという現象です
この現象はDeepFaceLabCUDA10.1AVX_build_06_20_2019では起きていません
もし、理由がわかれば教えて下さい
当方のPC環境は
CPU:Corei9 9900K
メモリ:32GByte
ストレージ:nvme M.2SSD 4Tbyte 2Tbytex2 RAID0
GPU:NVIDIA Geforce RTX2080ti 11GByte
よろしくお願いします
data_dstが6桁以上とはすごい長さですね!
そこまで長い動画は作ったことがないので、申し訳ないですが分かりかねます。
確かに、長さ制限ってあるのか気になりますね。また分かったら記事のほうに追記します。
試してみたところ、99999.pngの次に100000.pngが出力されると、マージ順としては100000.pngの次に99999.pngが来てしまっているように見えます。
前回の回答ありがとうございました!助かりました!
また質問させて下さい。
Src、dst共にloss値が下がらずに困っております。それぞれ0.36と0.29前後で推移しています。トレインは25万回で、src内の画像はフルHDで手動で厳選後、sortのbestで厳選しました。画像数は3800枚でGANは徐々に高めていき1.0から3.0に変更しても下がりません。RTX2060 6Gを使用しています。ご指導いただけるとありがたいです。よろしくお願い致します。
25万回も学習していたら、それなりにできあがってきてるのではないかと思います。プレビューウィンドウの顔画像が鮮明になっていればLOSS値に関わらず一度、mergeしてみてください。
質問ですLearn maskをオンで学習してます、これをオフにしたいのですがオンでスタートしたら学習設定の変更はできないのでしょうか
一度、trainを終了して、再度train開始時にオプションで無効にできたかと思います
↑管理人さま
申し訳ございません。書く場所を間違えました。削除してください。
管理者様
お世話になります。
初めてご使用させていただきましたが、6) train SAEHDを実施したところ以下の表記となり行えませんでした。
ImportError: DLL load failed: 指定されたモジュールが見つかりません。
Failed to load the native TensorFlow runtime.
See https://www.tensorflow.org/install/errors
for some common reasons and solutions. Include the entire stack trace
above this error message when asking for help.
誠に恐れ入りますが、解決方法をご教授頂けましたら幸いです。
何卒よろしくお願い申し上げます。管理者様
お世話になります。
初めてご使用させていただきましたが、6) train SAEHDを実施したところ以下の表記となり行えませんでした。
ImportError: DLL load failed: 指定されたモジュールが見つかりません。
Failed to load the native TensorFlow runtime.
See https://www.tensorflow.org/install/errors
for some common reasons and solutions. Include the entire stack trace
above this error message when asking for help.
誠に恐れ入りますが、解決方法をご教授頂けましたら幸いです。
何卒よろしくお願い申し上げます。
恐らくCUDA関連のエラーかと思います。
申し訳ないですが、載せていただいたエラーメッセージだけですと、単にエラーが出てることしか分かりませんので、何が原因か分かりかねます。
初めまして。当サイト大変参考になりました。
初めて8) merged to mp4 を実行してみたところ、書き出されたmp4は 音声はdata_dstのものと変わらないのですが、何故か画像の方だけ約2倍速で再生されてしまいます。
よくよく見てみるとresult.mp4と同時に生成されたresult_maskの長さが半分になっていました。
これが原因かと思われますがどうしたら解決できますでしょうか?
何が原因かまでは分かりかねますが、result_maskは「8) merged to mp4 」を実行した際に、完成した動画と一緒に生成されます。
ですので、result.mp4が何かの原因、悪さをしているということはないです。
断定できませんが、もとのdata_dst.mp4に起因するような気がします。
一同、他の動画でも同じ現象がおきるか試してみてください。
質問なのですが
train時のプレビュー画面で5個画像が横に並んでるうちの一番右側の画像の
顔の真ん中が赤くなってしまい、うまく二つの画像が合成されてないように見えるのですが
これは学習を進めていくうちになくなるのでしょうか。
何回ほど学習した状態でしょうか。
まだ回数が少ない(数百~数千回)だと、まだ顔がしっかりと形成されないのは正常ですが、
学習がしっかり進んでそのようなことが起きるのであれば何かしら問題があると思います。
学習を十分に(数万回)進めても改善されないようでしたら、別の素材でもtrainしてみて同様の現象が起きるか確認してみてください。
DeepFaceLab自体が正常に動いている場合に発生する、顔が上手く生成されない等はの問題は素材に起因していることが多いです。
2万回学習を進めたのですがしっかりと形成されていないので
ほかの素材を使用したところ正常に動きました。
丁寧なご返答ありがとうございます。
返信ありがとうございます。
私の使っていたdata_dstの動画はWindows10標準ソフトのGame DVR でキャプチャしたものでした。試しに他のmp4で試してみたところ、Game DVRの物では2倍速再生の不具合が起き、それ以外では無事に動画を生成することができました。
data_srcについてはGame DVRを使ったデータでも問題を起こさない様なので、
「data_dstにGame DVRは使わない」ということで解決しました。
試してみたのは以下のバージョンです。
DeepFaceLabCUDA10.1AVX_build_06_20_2019
DeepFaceLab_NVIDIA_build_04_13_2020
DeepFaceLab_NVIDIA_build_04_15_2020
アドバイスありがとうございました。
初めまして、当サイトを参考にさせていただいております。
質問なのですが、data_dstのaligned_debugではほとんどのフレームで顔認識しているのに、いざmerge SAEHD実施してみるとmerged_maskで顔の部分が抜き出されていないものが多く、mergedに書き出されるものがほとんど元のdstの顔になってしまいます。学習は30万回を超えています、Loss値もsrc、dst両方とも0.1台からの実施です。顔自体はきちんと生成されていると思います。私の少ない知識で考えてみて、原因としては①素材の動画が粗い②対象となる顔が小さいなどではないかと思っています。ただ解せないのが、同じようなフレームで顔の部分が結構大きいものなのにsrcが反映されたりしなかったりするものもあります。デボットの顔認識がきちんと生かされないのが非常に残念なのですが、いかがなものでしょうか。原因について推測を含めてでよいので管理人様のわかる範囲でご教授ください。
当たり前の話ですが、src・dstともに、alinedフォルダ内に書き出されている顔画像はすべて顔認識されています。
(aligned_debugで顔認識されているものも同じです)
data_dst > alinedに顔画像が書き出されているフレームで、mergeしたときに顔画像が合成されない場合は、何らかの問題が起こっていると考えていいでしょう。
私も以前同じような現象が発生したことがありますが、原因は分かりませんでした。
ただし、新しくDeepFaceLabフォルダを作りなおしたら、同じ素材でも問題なくtrain・mergeできました。
明確な根拠はありませんが、clear_workspace.batでクリアしてましたが、DeepFaceLabのフォルダを使いまわしてことが原因かもしれません。
早々のご返答ありがとうございました。早速管理人様のおっしゃったようにフォルダ作りなおして作業したところお陰様でうまく出来ました、ありがとうございました。ただ、斜めの角度や目をつぶっているところがうまく描写できていません。これはトレーニング不足ということでしょうか。それに該当するような画像をたくさん入れてtrainすれば解決することは可能なのでしょうか。管理人さんのご意見をお聞かせください。
「斜めの角度や目をつぶっているところがうまく描写できていません。これはトレーニング不足ということでしょうか。それに該当するような画像をたくさん入れてtrainすれば解決することは可能なのでしょうか。」これを改善できるのは後者しかありません。いくら学習しても、data_srcにその角度の画像がなければ、再現することはできません。
管理人様、ご返答ありがとうございます。理解いたしました。
また分からないことが出てきましたら質問させていただきます。
動画から動画を全フレーム画像で取得し顔部分を抽出したあとtrainさせているのですが、パソコンの容量が気になってデータを消したいのですが
trainとmerged to mp4.batを行う際に消しても影響のないデータなどはわかりますでしょうか。
消しても良いのはdata_srcの動画から書き出した画像のみです。それ以外は消してはいけません。「data_src > aligned」の顔画像も消してはいけません。
PCの容量が気になる場合は、動画から書き出す画像を次回からPNGではなくJPEGにするぐらいしか方法はありません。
初めましてこのサイトを頼りにしております
質問が1点だけあります
・data_src(10000枚) 「女優A」
・data_dst (11000枚) 「女優B」
この内容で10万回ほど学習させています。
ここで一度中断し動画を作成したところ概ね満足なのですが、まだまだ続けて学習させたいと思っています。
ですがその前に、data_dstの方を今と異なる「女優C」の素材に変えてそちらでも動画を作ってみたいと思いました。
こういった場合
1.data_dstのディレクトリを手動バックアップ(ディレクトリ名を変える等で退避)
2.data_dstに「女優Cの映像より画像化して格納」※ソート後に不要な画像は手動削除
3.またtrainを開始し10万回程学習させる
こういった手順でなければそれなりの動画は作れないものなのでしょうか?
それとも3.のtrainは既に不要だったりするのでしょうか?
そもそもこの手順で問題ないのかがわかっておらずお勧めの手順等ありましたら教えていただければと思います。
DeepFaceLabのモデルは残念ながら、汎用性の高いものではありません。
例えば、data_srcを人物A、data_dstを人物Bにして学習させたとします。このときに学習させたmodelはこの組み合わせでしか使用できません。
人物Bを人物Aに変換するためだけのmodelですから、当然です。
しかも、同じ人物の組み合わせであっても、素材となる動画が別のものになれば、別途学習が必要です。
(同じ人物であれば、場合によってはある程度はうまく合成できますが、基本的に上手くいきません)
これは動画によって、光の環境が違ったり、色合い、コントラスト等も異なるからです。
ですから、data_srcが同じ人物であっても、data_dstが別の動画、別の人物になれば別途学習が必要です。
流用できるのは、data_srcの顔画像(aligned)のみでしょう。
初めまして
質問なのですが、最後の工程のmerged to mp4.bat で
MP4動画を出力はされるのですが、mp4だと再生されず(厳密にいえば動画プレイヤーは開くのですが、再生ボタンが押せない状態です)ほかの形式だと音声は再生されるのですが、画面が映らない(黒い画面)状態です。
動画はサンプルを使用しております。
ご助言願いませんでしょうか?
詳しい状態が分からないので、断言できませんが、プレイヤー側に問題はないでしょうか。
どのようなプレイヤーをお使いなのか分かりませんが、VLC media player等フリーのプレイヤーで再生できないか試してみてください。
お返事ありがとうございます。
すみません。自己解決しました。
原因はマージがうまく出来ていなかったみたいで、
そのせいで結合出来ず、動画作成できないというものでした。
非常に参考になる記事で助かっています。ありがとうございます。
細かい指摘となるのですが、merge時のオプションの「[0] Choose output face scale modifier」の説明ですが、正しくは
– マイナスであるほど合成する顔が大きくなる
– プラスであるほど合成する顔が小さくなる
であると思われます。
ご指摘の通りです。ありがとうございます。
私が見た英語の文献が逆だったので、そのままになったままでした、修正させていただきす。
教えてください。
初めて作成をしてみたのですが、本来100秒ほどある動画が10秒ぐらいの早送りのような状態の動画として作成されてしまいます。
とりあえず試してみたくてあまり学習をさせなかったのですがそれが原因でしょうか?
それともほかに問題はあるのでしょうか?
学習の進度によって、完成した動画(result.mp4)の再生速度が変わるということはありません。
断定はできませんが、もとのdata_dst.mp4に起因する可能性が高いです。
以前、「2倍速で再生されてしまう」とコメントされていた方は、data_dst.mp4にWindows 10のGame DVRでキャプチャした動画を使用したのが、原因だったとのことです。
ありがとうございました。
どうやらdata_dst側の動画に不具合があったようです。
別の動画で試したら問題なく作成できました。
大変参考になるページ、ありがとうございます。質問させていただけますか。
CUDA_ERROR_OUT_OF_MEMORY: out of memory
と出て、trainができない状況で困っています。すべてENTERで初期設定です。
DFLの1.0では問題なく起動できていたのですが・・・
スペックはRyzen7 2700XとMSI-GeForceRTX2700Sです。
スペック不足とも判定できず、どんな原因が思い当たるか、
もし思いつきましたらお教えくださいませ。
Train時の設定値に問題があるのではないでしょうか。
解像度を下げる、バッチサイズを下げる、アーキテクチャをHD版のDFHD/LIAEHD指定していたら、DF/LIAEに変更する等してみてください。
DFL 1.0で正常に動いていた設定値と同じ設定値なら、DFL 2.0で動くという訳でもないので、ご注意ください。
ありがとうございます。
LIAEHDをLIAEにすることでとりあえず動きました。
色々いじってみて最適な数値を探ったほうがよさそうですね。
ありがとうございました。
いつも参考になる記事をありがとうございます。
現在、学習が始まらなくて困っております。すべてのオプションを入力し終わり、文字列が自動で出てくるのですが、最後の行に
TypeError:’NoneType’ object is not iterable
と表示され、学習が始まりません。何が原因で学習が始まらないのでしょうか。そもそもこのエラーコードだけで原因がわかるのでしょうか。
このDeepfacelabに触れるのも、このようなことをするのも初めてなので、初歩的な質問となっていることをご容赦ください。ご教授いただけると幸いです。
同じような症状の例が海外のフォーラムにありました。
原因は分かりませんが、deepfacelabのフォルダを新しくexeから解凍しなおしたものを使ったら正常に動いたと書かれていました。
一度、試してみてください。
教えてください。
移植する側の人物の顔画像ですが、
AE architectureを現在DFを使用しているのですが、
同じ人物でをLIAEに変更する場合その変更設定の仕方がわかりません。
どのタイミングで、どのようで設定変更するのか教えてください。
初歩的な質問で本当に申し訳ありません。
参考にさせて頂いております。
質問なのですが、複数台で同じものを同時にtrainし、後で合わせる事は可能なのでしょうか?
全く同じ素材を、同じ設定で別のPCで同時に学習すると、基本的には学習したmodelも学習の進度も同じ結果になりますから、特に意味はありませんし、学習したmodelを結合する機能などもありません。
複数のPCを利用して、学習が進むのを早くしたいという趣旨でしたら、複数のマシンを使うのではなく、ビデオカードを2本差しするのが良いかと思います。
こんにちは、サイト大変役に立っており感謝しております。
2本差しの件について、deepfakeにおける有効性についてはご存じでしょうか?。もしパフォーマンスが2倍近くになるなら、例えば1080ti×1枚より1070ti×2枚指しのほうがコスパが良くなると思いますが、いかがでしょう。有志の報告例に2枚指しのデータが載っていますが、同じ条件での比較例がなく、どうにも判断が難しいです。
よろしくお願いいたします。
この点についてはデータがないので、なんとも言えません。
1070 ti はVRAMが8GB、1080 tiはVRAM 11GBですから、1070 tiを2枚刺しすれば、VRAM 16GBとなるとので、1080ti 1枚よりもVRAMは多くなるので、trainを実行できる解像度、バッチサイズは大きくなると考えて良いと思います。
ただし、1080tiのほうがメモリクロックが高いので、反復時間は1080 tiのほうが短くなると思います。
アルファチャンネルの設定は 2.0だとなくなったのでしょうか?
== 28.01.2020 ==
Improvements for those involved in post-processing in AfterEffects:
Codec is reverted back to x264 in order to properly use in AfterEffects and video players.
Merger now always outputs the mask to workspace\data_dst\merged_mask
removed raw modes except raw-rgb
raw-rgb mode now outputs selected face mask_mode (before square mask)
‘export alpha mask’ button is replaced by ‘show alpha mask’.
You can view the alpha mask without recompute the frames.
8) ‘merged *.bat’ now also output ‘result_mask.’ video file.
8) ‘merged lossless’ now uses x264 lossless codec (before PNG codec)
result_mask video file is always lossless.
Thus you can use result_mask video file as mask layer in the AfterEffects.
DeepfaceLab2.0では、mergeしたフレームを動画にする、「8) merged to mov lossless.bat」「8) merged to mp4 lossless.bat」「8) merged to mp4.bat」を実行すると、result.mp4と一緒に、同じ長さのresult_mask.mp4というマスク領域を示した動画が書き出されます。これをAfter Effects等の動画編集ソフトで、マスクとして利用できるようです。
ありがとうございました
7) merge SAEHD.bat
Choose mask mode: のとこでFAN-dstの項目が出てきません
Choose mask mode:
(1) dst
(2) learned-prd
(3) learned-dst
(4) learned-prd*learned-dst
(5) learned-prd+learned-dst
(6) XSeg-prd
(7) XSeg-dst
(8) XSeg-prd*XSeg-dst
(9) learned-prd*learned-dst*XSeg-prd*XSeg-dst
こんな感じです
記事を書いた時は「build_02_28」を使っていますので、最近のbuildとはオプション項目が異なるものと思います。
学習時に素材の顔の向きごとにフォルダ分けして学習させてるんですがモデルも顔の向き事に作って学習したほうがいいんでしょうか?それとも一つのモデルを使いまわしていいんでしょうか?
顔の向きごとに学習させなくとも、ちゃんと様々な角度から写した画像がdata_src内に含まれていれば、問題ありません。
DeepFaceLabをgoogle colabで使用する方法も今後記載頂ければ嬉しいです!!
私も最近知りまして気になっています、また近々掲載させていただきます。
お返事どうもありがとうございます。
メモリが16Gになるだけでもありがたいですね。
ただ、計算能力?は1080TIに劣ってしまうんですね。
CUDAコア数も2倍なら上回っているかと思いましたが、
そんなに単純じゃないんですね。
こんにちわ いつもありがとうございます。
教えて頂きたいのですが、train時のBatch_sizeについてなのですが
他は全部同じ設定にしたとしてBatch_sizeの大きさだけの違い
でどのくらい変わるものなのでしょうか?時間だけなのでしょうか?(例えばBatch_size8の時に10時間必要だったものが・4の時には同じ成果を出すのに
15時間とか?・12に設定した時は5時間とか?)正確で無くても大丈夫なので教えて頂けたら嬉しいです。
あと、batch説明の所にブレと書いてあるのですが、どのような意味なのでしょうか?
よろしくお願いいたします。
data_srcで検出された顔画像のうち、学習の邪魔になりそうなもの(顔が半分隠れてしまってるもの等)を削除したんですが、data_dstのほうは特に頑張って削除しなくても良いんですかね。data_dstのほうも品質を上げようとして相当削除したんですが、出来上がった動画は顔が変換されてないシーンが多い、チラつきが多いものになってしまいました…。
いつもお世話になっております。
train時のプレビュー画面の5番目では違和感なくできあがっているのに、
いざmergeすると前髪がかかって違和感のある画像に仕上がってしまいます。
オプションをseemlessに変えると、ある程度は違和感がなくなるのですが詰めが甘いというような状況です。
他wikiを見て「srcのmaskを手動設定」という記述を見つけたのですが”5.3) data_dst mask editor”はあってもsrc用のエディタがない場合はどのようにmaskを設定するのでしょうか。
エディタの使い方も一緒にご教授いただけると助かります。
もしくは他に良い方法があれば合わせて教えていただけると助かります
〇横からですがバッチを2倍にしてもloss値の低下速度が倍になるわけではないですね。
今現在、バッチ数だけ変えて進行速度の影響を確認していますが、速度への貢献度はかなり少ない印象です。(倍にしても+20%くらい?)しかも8batchくらいから速度は頭打ちになり、32batch以降はむしろ遅くなる結果になりました。この結果だけみると8バッチ以上にバッチ数を増やす意味がよくわかりません。
〇バッチの説明にあるブレというのはloss値のブレじゃないかと思います(青と黄色のグラフが縦方向に幅がありますよね、あれが縮まるのかと)。バッチ数増加に進行速度が速まる以外の効果があるなら私もお聞きしたいです。
ももも様 返信ありがとうございます。
本当に解りやすかったです!
少し前に、経験が少ない私なりに試してみたのですが、変わったのか?って感じで
よく解らなかったので質問させて頂きました。
ありがとうございました。
ももも様
私が返信する前に、ご説明くださりありがとうございます。
御礼申し上げます。
fansegがイマイチよくわからないんですが、やり方の簡単な流れみたいなものを教えて頂きたいです
data_dst>alignedに顔と手が被った写真がある場合data_src>alignedにも同様のポーズをした素材を用意すれば良いのでしょうか?
顔に手や物が被った画像はdata_src > aligned の場合は学習に適さないので削除します。data_dst > aligned の場合は、そのコマをmergeで合成しなくても良いなら削除。mergeで合成してほしい場合はtrain前に一旦、顔に手や物が被った画像をどこか別の場所へ退避させ、trainでは使用しないようにします。そして、trainを終えてmergeを始める前にdata_dst > alinedに戻します。これで学習に悪影響は与えず、mergeで合成することができます。しかし、基本的に顔を遮るものがある場合はうまく合成できないことが多いです。
公式にあるFANSEGラストビルドのを使えば、マージのオプションでFANSEGを選べば顔に手が被ったぐらいなら、余裕で合成してくれますね
最近のバージョンはFANSEGが廃止されてXSEGに移行してるので、簡単には行かなくなってるけど
そうなんですね。私自身あまり試したことがないので、これに関しては詳しくないんです。
ありがとうございます。
質問なんですがグラフィックボードのクワトロ8000RTX4枚挿しはしっかり認識してフル稼働出来ますか?( ╹▽╹ )
申し訳ないですが、やったことがないので分りかねます。
いつも参考にさせていただいております。
ffmpegを使用する場面においてデータがGPUに渡っていないようなので、試行錯誤していますがうまくいきません。皆さんはどうしていますか?
わたしの環境だけでしょうか?
「ffmpeg」を使用する場面というのは、mergeしたフレームを結合して動画にする「merged to mp4.bat」などを実行した際のことでしょうか。
ここではGPUにデータが渡ってなくても、動画ができていれば問題ありません。
自己完結しました。
\_internal\DeepFaceLab\mainscripts\
内の”VideoEd.py”
71、240、245の各行の”libx264″を”h264_nvenc”に変えることで
GPUで結合できました。
71行はおそらく「3) cut video (drop video on me)」
240、245はそれぞれ「8) merged to mp4 lossless」と「8) merged to mp4」に
関係しているようです。
私の環境では、30fps程出ました。
よろしければ教えてください。data_dstの人物がマイクや手で顔の一部が隠れているシーンがあったとします。この場合、alignedフォルダからその部分を削除してから、学習すべきでしょうか?
alignedフォルダから、train前に別の場所に移して、それからtrainを実行し、mergeを実行する前にalignedフォルダに戻すと良いかと思います。
お世話になっております。
顔に被る障害物があっても綺麗に処理してくれるXsegについてなんですが、今後Xsegについてのマニュアル記事を書く予定はありますか?
自分なりに試行錯誤してますがやり方がわからず使えずにいます。
XsegよりFansegの方が簡単という情報も得て試そうとしたのですが詳しい解説が無く使えずにいます。
この記事のバージョンでもmergeの際にFan-prd・Fan-dstがありますが、こちらを使用すると顔に被る障害物をある程度上手く処理してくれるのでしょうか?
もし綺麗に処理する為の方法などがあったら教えていただけるとありがたいです。
サイト主でなくてすみませんが。
Xsegならyoutubeの下の動画なんかどうですか?
海外動画ですが動画なので見るだけで何してるかわかります。
https://www.youtube.com/watch?v=1smpMsfC3ls
輪郭を指定する目的の動画ですが、障害物にも同じ要領で対応出来ました。
どこまでご存じかわかりませんが、まだ試してなければどうぞ。
返信ありがとうございます。
教えて頂いた動画を見て制作しようとしてたんですが、顔の輪郭設定で一度決めた輪郭を次の画像に反映させる事が出来なかったので今回質問しました。
動画では『Ctrl+D』や『Ctrl+A』などが表示されスムーズに設定されてるんですが、同じようにキーを押しても何もならなかったのでその辺を詳しく解説していただけるとありがたいです。
こんばんわ。疑問点の答えになっているかはわかりませんが。
指定した輪郭を他の画像に反映させる工程はtrain→applyで自動的に行われます(私はapplyを忘れていて似たような苦労をしました)。ショートカットキーを使わなくても出来たのでそこは特に関係ないと思います。
手順としては
editで輪郭指定(1画像でもよい)
editを閉じる(いきなり閉じても勝手に保存されている)
trainで輪郭学習
applyで適応(ここで反映される)
もう一度editを開く(すべての画像に学習後の輪郭がある)
変な輪郭になってる画像を探し輪郭指定(以下繰り返し)
です
ありがとうございます。
試してみます。
お世話になっております。
DFLを始めて今まで2週間程度ですが、20分程度の動画をシーン別にモデル作成をしようと思いdata_dst内のaligned・aligned_debug・画像を分けて数十秒~数分間分のフォルダを作成して実施してました。
はじめの方はそれなりにLOSS値が下がっていたのですが、何度かmodelフォルダを他に移動して新たなmodelフォルダで同じシーンを学習していたところ、顔認識設定のところでwfにしたあとでLOSS値がほぼ下がらなくなってしまいました。
もとのf設定に変更しても下がらないのですが、新規でmodel作成するときにmodelフォルダ内で動かさない方がよいものとかあるのでしょうか?
もしくはこの学習の前にシステムクリーナーを使用してしまったのが原因で学習内容がなくなってしまったとか?原因が分からないのですが、心当たりある方教えてください。
現在は、train SAEHDにて学習していますが、LOSS値の上にstrongly recommended to use a pretrained model to speed up the training and improve the quality.と言う通常学習では表示されないメッセージが出ています。そこで、一度pretrained modelで学習させてみましたが、そのあとでもやはり変わりません。
解決方法などあれば、ご教授願います。
30万くらい学習するとプレビューの一番右側の顔が目と口以外特に頬らへんがドット柄みたいになってしまうのですが同じ現象の人いますか?
対処方法知っていればお願いします。
data_srcを前髪が眉にかかっている動画を使うことは現実的ではないのですか?
1.0の頃の他の方の解説を見ると、できなくもないけど膨大な手作業が必要になる、と書いてありました。
後にHALF FACEでtrainさせるとしても、支障が出てしまうのでしょうか?
お答えいただけると嬉しいです。
dst、srcの処理済みです。
convert H128.bat でmergedにファイルが生成される際に顔のはめ込み部分にsrcのaligned画像とならず「青く四角い枠」となってしまいます。これまでにこのような事はありませんでした。
気になる事といえば、train開始時のプレビュー画像は正常でしたが、しばらくたって確認した時から、2,4,5列が真っ白になっていた事です。それからおかしい気がします。
それ以後はtrainとスタートしても、進んでいるにもかかわらずずっと真っ白なままとなってしまいました。
何かこれと関係はあるでしょうか?
ちなみに現在は1744000の学習済みです。よろしくお願いいたします。
お世話になっております。
前回質問させていただいた者ですが、色々と試してみたのですが改善されませんでした。
症状としては、始めの数百枚はLOSS値も順調に下がって1.0台にまで落ちてプレビューも通常通り表示されるのですが、5分程度学習すると突然srcは11.0台、dstは9.0台に上がってしまいプレビュー画面も初期の顔画像のみで2列目・4列目・5列目がなくなってしまいます。そのあと1日以上10万回以上学習してもLOSS値が上下するだけで変化がありません。
DFLフォルダーを再展開したり、色々と思考錯誤しているのですが、どうして学習できなくなったのか見当がつきません。
数日前までは、問題なくできていたしmergeまで出来ていたので何が原因か不明です。
使用グラボはGeForce RTX2070を使用しているので、問題なく動く機種のはずなんですが、、、
何卒、宜しくお願い致します。
6) train Quick96.bat
VRAM 4GB以上のローエンドGPU用。軽量版の学習モード。一応、それなりに学習させることはできますが、解像度が96×96ピクセルのため
と書いてありますが、
6) train SAEHD.bat
こちらのモードで解像度64に設定したら6) train Quick96.batより質が落ちるとゆうことになりますか?
変な質問だったらすみません。
質問失礼します。
例えば人物A→Bについてある程度満足し、
次に人物A→Cの動画を作成しようとする場合、
dst内の画像類をすべて削除してdstだけ全過程をやり直すことになると思われます。
この場合、一度削除する手前、二度と人物A→Bを追加でトレーニングさせたいと思っても戻ることはできないのでしょうか?
どなたかにお尋ねしたいのですが、「aligned」フォルダから誤検出した画像を削除する際、それに対応する画像を「aligned_debug」からも削除したほうが良いのでしょうか?
両フォルダとも削除しなければならないとすると手間が二つになり大変なのですが、もし仮に「aligned」フォルダからのみ削除しておけば「aligned_debug」からは削除しなくても上手くいくということならだいぶ楽になんですよねぇ…
「aligned」フォルダからのみ削除しておけば、問題ありません。
初めまして。
train時に
IndexError: index 3 is out of bounds for axis 0 with size 3
というエラーが出てしまい、trainが開始されません。
解決策等ご存じでしたらご教授お願いします。
配列のサイズを超えて代入するとこのようなエラーが出ます。train時のオプションのどこかの値が大きすぎる可能性があります。
train時GPUを選択してるんですが使用率がCPUより低いんですがこれは普通なんでしょうか?
タスクマネージャーで見たところ
PythonのCPU使用率50~60% GPU使用率10~20%となってます
注目すべきはGPU使用率ではなく、GPUのCudaの使用率です。これが使用率7~9割ほどになっていると思います。
RTX30シリーズは対応していないみたいですね。
こちら側で対処策等あるのでしょうか。
少し待てば、RTX30シリーズでも使えるよう改良がなされるかと思います。
気長に待つことにします!
開発者スレッドでtest版がでていましたよ。
ttps://github.com/iperov/DeepFaceLab/issues/906
すでに30xx持ってる人は試してみてはどうでしょう。
私もやってみましたが相当早くなりますよ。
pretrain modelの導入がうまくいきません。
2020.0802の最新版でdf-udのpretrain modelを動かしてみました。
アーキテクチャは対応しているはずです。
英語版では、ダウンロードしたmodelを所定位置に配置し、
pretrain modeをnにしたら普通に動くとのことでしたが、
一応、読み込んではいるものの、真っ白からのスタートになります。
真っ白からにしては目鼻口の生成が早い気がしますが、
そういうものなんでしょうか?
何かご存じでしたらご教示ください。
こんにちわ いつもありがとうございます。
動画からaligned顔画像を切り出す前に最初に行う 2) extract images from video data_src の作業でworkspace>data_src に出来る大量の静止画像ファイルは消しても問題なく、今後何かに使用することは無いのでしょうか?
data_dstの全静止画像ファイルは、動画にする時に必要だったと思うので消したらダメだと思うのですが、srcのは使い道が無いですよね?
あと、何個か前の返信であった、GPUのCudaの使用率はどうやって確認するのでしょうか?色々ググってみたのですが分からなかったので教えていただけると嬉しいです。
よろしくお願い致します。
タスクマネージャ→パフォーマンス→GPU で適当なグラフ(3DとかCopyとか)の名前をクリックしてCudaを選択
data_srcのaligned画像が、trainすると異様に暗く読み込まれてしまい、train結果も顔がかなり暗くなってしまうのですが原因が分かる方いらっしゃいますか…?
Cudaの使用率はタスクマネージャーの専用GPUメモリの枠だと思われます。
タスクマネージャーのみで見るとパフォーマンスはそこまで使用率は高くありませんが、afterburnerなどのグラボ制御ソフトで見るとtrain中はがっつり使用率が上がっているのが確認できます。
CUDA使用率の確認方法ですが、タスクマネージャーから「パフォーマンス」タブを開き、「GPU」を選択すると、いくつかのリアルタイム折れ線グラフが表示されます。
そのうちどれか一つのグラフ標目をクリックすると、「CUDA」が選択できますよ。
rtfb6uh様 ごめんなさい 今気付きました・・・
教えて頂いたCUDA使用率の確認方法を実行してみたら出ました!
ありがとうございます。
workspace>data_src に出来る大量の静止画像ファイルは消しても問題ないです
data_src\alignedはもちろん必要です
タスクマネージャー→パフォーマンス→GPU→専用GPUメモリ使用量が
DeepFaceLab使用前と使用中とで、大きく増えているかと思います
ELSA System Graphと言うフリーソフトを導入して
GPU Loadを見れば、DeepFaceLab使用前と使用中とで、大きく増えているかと思います
プレビュー画面がおかしくなるのは、モデル崩壊、モデルが壊れたと思われます
最新版とか新しい版を使用したりすれば、起こらないはずなのですが
モデルのバックアップがあれば、そこから復旧できる可能性はありますが
同じ版のDeepFaceLabを使用している限りは、長くTrainすればモデル崩壊するでしょう
最新版とか以外は、作者は未サポートです
昔の版では、モデル崩壊もよく起こっていたそうです
srcごとにモデルを作成して分けますから、同じモデルのまま非常に長くTrainする事は無いはずなのですが
Loss値とかが下げ止まっているのに、Trainをやめないのでしょうか?
プレビュー画面が似ているのに、Trainをやめないのでしょうか?
dstの顔画像に対応するsrcの顔画像
顔の画角、横向き度、上向き下向き度が無ければ、src不足なので、そもそも生成されません
現在のAIは1つの事しかできません
DeepFaceLabに、正面顔から横向き顔の生成機能はありません
srcが不足していれば、いくら学習しても無駄な物があります
正面顔近く、カメラ目線しか、似ない事も多いです
1回Trainをやめて、Mergeしてみてはどうでしょうか?
dst動画は、あまり顔のカメラアングルが厳しいシーンは、srcを用意するのが難しいです
dst動画の時点で、似ないと思われる、自分が似せたことが無いシーンはカットしてもよいです
完成後の動画で、似ていないシーンはカットしてもいいです
srcが準備できなければ、いくらTrainしても似ません
data_srcを前髪が眉にかかっている動画を使うことはできます
DeepFaceLab 2.0の最新版とか使用する必要があります
Xsegエディターでsrcをマスクします
前髪は顔では無く、顔の前の邪魔な障害物なので、顔から外します
顔の部分をXsegエディターでお絵かきします
顔の主な角度ごと、瞬きしたらとかで、何枚かXsegエディターでsrcをマスクします
Xseg Trainします
Xsegエディターは最新版とかで簡単に使用できる様になりましたよ
一番左上のアイコンで顔の範囲、前髪を除く額、眉毛、目、鼻、口の顔のパーツを含む
顔の輪郭(頬から顎にかけて。額も含む。前髪は除く)をお絵かき
一周して始点と終点が同じになる様に囲む
左上二番目のアイコンで、顔の範囲にある、顔ではない邪魔な障害物をお絵かき
一周して始点と終点が同じになる様に囲む
舌、眉毛にかかっている前髪、顔の前にかかっている手など。髪は顔ではありません
本家フォーラムに、Xsegマスク済の顔画像が複数あり、ダウンロードできます
その顔画像を使用して、Xseg Trainしても、相当な物ができます
うまくいかなかったコマから、更に絞って、自分でXsegマスクすればいいです
DFLの最新版を使用して、同じsrcとdstのペアで、4日間以上もTrainしているのは
何かおかしいはずです
本家フォーラムに、必要なsrc枚数の目安、上限など
必要なTrain回数の目安など書いてあります
必要なTrain回数を大幅に超えているのはなにかおかしいです。srcの画角不足などで
もともと似ないはず、無駄なはずとか
本家のガイド、チュートリアル、FAQは一度目を通したほうがいいはずです
顔画像は512×512とかで抽出しても問題は無いです
学習時に最大でも256×256とかでしか学習できないでしょう
学習時に指定した解像度で学習します
DFL2.0最新版は随分と軽くなりました
random_warp: Trueで学習→random_warp: Falseで学習→lr_dropout: yにするだけです
DeepFaceLabで日本語のサイトばかりを検索しない方がいいと思います
英語のサイトが本家でもあり、英語はChromeのGoogle翻訳で十分に読めます
日本の場合は事情もありますし
RTX 3000ですが、Tensorflow-2.3.0でまだ動作しないようです
Tensorflowの版数アップでいずれサポートされるでしょう
DFLが対応できたとしても、当然その後です(DFL1.0は当然未サポート)
GTX、RTX2000とは別プログラムになるのではないでしょうか?
二重にサポートできるとも思えませんが
GPU関連プログラムは、すぐに互換が無くなり、書き替えですし
Mega.nzにDeepFaceLab_RTX_3000_build.exeが上がっていましたね
CUDA11も同梱している様です
いずれにせよ、SAEHD、Xsegなので、DeepFaceLab_NVIDIA_08_02_2020使用できない人には無意味
frame= 94 fps=1.6 q=-1.0 Lsize= 75283kB time=00:47:53.00 bitrate= 214.7kbits/s speed=48.1x
video:6268kB audio:68485kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.709377%
[libx264 @ 000001b34ed4cbc0] frame I:1 Avg QP: 2.55 size:155102
[libx264 @ 000001b34ed4cbc0] frame P:24 Avg QP: 2.03 size:124432
[libx264 @ 000001b34ed4cbc0] frame B:69 Avg QP: 4.29 size: 47480
[libx264 @ 000001b34ed4cbc0] consecutive B-frames: 1.1% 2.1% 3.2% 93.6%
[libx264 @ 000001b34ed4cbc0] mb I I16..4: 21.9% 24.8% 53.4%
[libx264 @ 000001b34ed4cbc0] mb P I16..4: 4.8% 5.0% 10.7% P16..4: 41.3% 13.1% 15.4% 0.0% 0.0% skip: 9.7%
[libx264 @ 000001b34ed4cbc0] mb B I16..4: 0.4% 0.7% 2.0% B16..8: 34.6% 7.5% 4.3% direct:17.6% skip:32.8% L0:42.0% L1:46.5% BI:11.4%
[libx264 @ 000001b34ed4cbc0] final ratefactor: 2.28
[libx264 @ 000001b34ed4cbc0] 8×8 transform intra:24.3% inter:25.5%
[libx264 @ 000001b34ed4cbc0] coded y,uvDC,uvAC intra: 84.2% 76.0% 65.2% inter: 45.0% 28.7% 27.2%
[libx264 @ 000001b34ed4cbc0] i16 v,h,dc,p: 34% 24% 28% 14%
[libx264 @ 000001b34ed4cbc0] i8 v,h,dc,ddl,ddr,vr,hd,vl,hu: 31% 22% 21% 4% 3% 4% 4% 6% 4%
[libx264 @ 000001b34ed4cbc0] i4 v,h,dc,ddl,ddr,vr,hd,vl,hu: 38% 24% 12% 5% 5% 4% 4% 5% 3%
[libx264 @ 000001b34ed4cbc0] i8c dc,h,v,p: 54% 17% 24% 6%
[libx264 @ 000001b34ed4cbc0] Weighted P-Frames: Y:0.0% UV:0.0%
[libx264 @ 000001b34ed4cbc0] ref P L0: 71.5% 5.7% 15.2% 7.6%
[libx264 @ 000001b34ed4cbc0] ref B L0: 88.5% 8.9% 2.6%
[libx264 @ 000001b34ed4cbc0] ref B L1: 97.0% 3.0%
[libx264 @ 000001b34ed4cbc0] kb/s:16368.93
[aac @ 000001b34f4522c0] Qavg: 566.413
Done.
最後にresult動画生成しようとしたが10秒くらいで終わってしまう
上記のようなエラー?がでるんだけど、何が問題ですか?
frame= 94 fps=1.6 q=-1.0 Lsize= 75283kB time=00:47:53.00 bitrate= 214.7kbits/s speed=48.1x
video:6268kB audio:68485kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.709377%
[libx264 @ 000001b34ed4cbc0] frame I:1 Avg QP: 2.55 size:155102
[libx264 @ 000001b34ed4cbc0] frame P:24 Avg QP: 2.03 size:124432
[libx264 @ 000001b34ed4cbc0] frame B:69 Avg QP: 4.29 size: 47480
[libx264 @ 000001b34ed4cbc0] consecutive B-frames: 1.1% 2.1% 3.2% 93.6%
[libx264 @ 000001b34ed4cbc0] mb I I16..4: 21.9% 24.8% 53.4%
[libx264 @ 000001b34ed4cbc0] mb P I16..4: 4.8% 5.0% 10.7% P16..4: 41.3% 13.1% 15.4% 0.0% 0.0% skip: 9.7%
[libx264 @ 000001b34ed4cbc0] mb B I16..4: 0.4% 0.7% 2.0% B16..8: 34.6% 7.5% 4.3% direct:17.6% skip:32.8% L0:42.0% L1:46.5% BI:11.4%
[libx264 @ 000001b34ed4cbc0] final ratefactor: 2.28
[libx264 @ 000001b34ed4cbc0] 8×8 transform intra:24.3% inter:25.5%
[libx264 @ 000001b34ed4cbc0] coded y,uvDC,uvAC intra: 84.2% 76.0% 65.2% inter: 45.0% 28.7% 27.2%
[libx264 @ 000001b34ed4cbc0] i16 v,h,dc,p: 34% 24% 28% 14%
[libx264 @ 000001b34ed4cbc0] i8 v,h,dc,ddl,ddr,vr,hd,vl,hu: 31% 22% 21% 4% 3% 4% 4% 6% 4%
[libx264 @ 000001b34ed4cbc0] i4 v,h,dc,ddl,ddr,vr,hd,vl,hu: 38% 24% 12% 5% 5% 4% 4% 5% 3%
[libx264 @ 000001b34ed4cbc0] i8c dc,h,v,p: 54% 17% 24% 6%
[libx264 @ 000001b34ed4cbc0] Weighted P-Frames: Y:0.0% UV:0.0%
[libx264 @ 000001b34ed4cbc0] ref P L0: 71.5% 5.7% 15.2% 7.6%
[libx264 @ 000001b34ed4cbc0] ref B L0: 88.5% 8.9% 2.6%
[libx264 @ 000001b34ed4cbc0] ref B L1: 97.0% 3.0%
[libx264 @ 000001b34ed4cbc0] kb/s:16368.93
[aac @ 000001b34f4522c0] Qavg: 566.413
Done.
最後にresult動画生成しようとしたが10秒くらい(いつも同じところ)で終わってしまいます。
上記のようなエラーがでるんですけど、何が問題ですか?
resultで出来上がった動画は4秒ぐらいで残りは音声のみになります。
原理的に、顔の輪郭、髪型は入れ替わらないので、srcとdstの相性があり
似ない物は似ませんね
H128やDF系だと、正面顔近くの物でないと、似せるのは難しいかと思います
顔認識で、髪は顔ではなく、顔の前の邪魔な障害物ですね
表情のモーションもあり、似ないdstは似ませんね
顔認識、顔学習において、顔とは、眉、目、鼻、口、髪のかかっていない頬から顎にかけての輪郭ですね
顔のパーツの輪郭形状で顔の特徴を抽出していると思われます
計算量削減のため、顔をモノクロ画像化、白黒二値化、顔のパーツの輪郭抽出
色合わせは別途
dstの顔にsrcの眉、目、鼻、口を貼り付けますね。福笑いです
顔の横向き度、上向き下向き度が違っていれば、貼り付けてもおかしな事になりますね
kyouko_magica様
詳しく教えてくださり ありがとうございました。
SAEHDのLIAE-UDとかは似せに行く強引さがありますね
DFより時間はかかります
srcだけの学習 src全てdstは適当に1枚 R/W OFF srcのモデルと作成しバックアップコピーします
そのモデルに対しdst×dstで学習します
dstの舌、前髪が再現できるまで回します
srcを本番の物に替えます。srcは前髪あり、なし両方が望ましいです
srcが戻ってくるまで時間はかかりますが、Xsegマスクしなくても
舌、前髪などはXsgマスクなしで再現できます
Mergeの時に、srcとdstのandにするので、srcは前髪あり、なし両方が望ましいです
自分は横顔が似せるのが難しいです
srcの横顔があっても仕方が無いので、
srcをyawでsortして、srcの横顔を退避しています
srcの枚数が少なくなり、学習が速くなります
似ない似ないと言う人は
aligned_debugの下の画像を確認して、LandMarkが当たっているか確認した方がいいです
顔の角度が厳しいなどで、緑の線で眉、目、鼻、口、グレーで顔の範囲
がしっかり見えないと、顔認識がうまくいっていません
うまくいっていないaligned_debugの下の画像を削除して
5) data_dst faceset MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.batで顔の手動抽出が必要です
srcも同様です。顔抽出時にaligned_debug作成できますから(最新版)
5) data_dst faceset MANUAL RE-EXTRACT DELETED ALIGNED_DEBUG.batを元に、
batの中身をdst→srcに変えればよいです
手動抽出でもうまくいかない場合は、そのdst、そのシーンはdstに向いておらず、似ません
かなり上向きの顔で目玉が見えていない顔
かなりうつむきの顔で目玉が見えていない顔
などは、似せに行ったところで、本人かどうかわかりません
いっそのこと、別人の顔を使用するのもありです
大勢の日本人の若い女性とかで、混ぜて、色々な顔を学習して、平均顔を作成して
そのモデルから継続して、各srcのモデルを作成するのもありかと思います
\workspace\data_dst.mp4は必要です
\workspace\data_dstの下の動画コマの枚数分だけ
\workspace\data_dst\alignedに顔画像がありますか?
\workspace\data_dst\aligned_debugの下で、顔パーツの緑目印(ランドマーク)
グレーのマスク、赤四角、青四角はありますか?
フリーソフトですから、フォーラムや掲示板などで、ユーザーどうしがサポートしていますよ
ここは初心者向け一通りの作成方法解説のみだと思いますよ
H128やDF系などでは
あえて目瞑り、半目顔をsrcから取り除いて学習すれば
dstが目瞑り、半目でも、完成動画は目を開かせることができます
それで違和感がなければ、Fakeなのでそれもありかと思います
あえて笑顔しかsrcで用意しなければ、完成動画も笑顔のみになるかと思います
Loss値が下がったところで、srcとdstの相性が悪ければ、似ないと思います
srcとdstの顔画像をsrcフォルダに混ぜて、yawでsortして、dstに無いsrcのyaw
右横顔すぎる、左横顔すぎるとかは削除した方が、結局は学習が速いと思います
pitchでsortして、dstに無いsrcのpitch、上向き顔すぎる、俯き顔すぎるとかは削除した方が、結局は学習が速いと思います
dstにあって、srcにyaw、pitchが無ければ、そのコマは似ない訳ですし
機械学習なので、過学習、モデル崩壊の可能性があります
1.古い版は不具合の可能性があり、避ける
2.学習を途中で打ち切る(学習回数やLoss値が目安)
3.SAEHDでRandom Warp True→False→lr dropout True(VRAMは食うが、過学習防止、学習効率アップ)
Loss値が下がる=似る でもないです
srcとdstの相性とかありますし
質問失礼します。
当方MacBook Proを使用しているのですが外付け GPU(e GPU)を用いてNVIDIAのGPUを接続した場合は異常なく作業はできますか?
こんにちわ 教えてください。
train時のオプションの [y] Enable random warp of samples ( y/n ?:help ) :
を今までデフォルトのYから変えたことがなく、同じmodelファイル?を何人もの
SRCやDSTに使いまわしていて数百万回trainしていて
今後もそのmodelを使いまわして行く予定なのですが
途中で[y] Enable random warp of samples ( y/n ?:help ) :をYからNに変えたり戻したりしても問題ないのでしょうか?
modelの崩壊?など・・・今まで変になった事が無いので崩壊がよくわかりませんが。
先ほど少しだけ試してみたのですが、今まで減りにくかったLOSS値が減りやすかったですが、一時間くらいの短い時間を回しただけでは,そこまでの画像の変化は無かった様に思いますが、細かな所も学習してくれる(どんな?)なら YからN にした方がいいのでしょうか?
よろしくお願いいたします。
途中で[y] Enable random warp of samples ( y/n ?:help ) :をYからNに変えたり戻したりしても問題ないです
yで機械学習用の顔データの水増しとかやっているみたいです
顔画像を少し回転とか、二値化のしきい値変化とか
モデルの汎化能力が高まります
yのままだとLoss値が一定以上に下がらないので、プレビューで十分に似たら
nにすれば、ピクセル値も含めて似て、Loss値が下がります
その後、lr_dropout yにすれば、学習が速くなり、過学習防止になります
VRAMを食うので、Batch数が下がり、最後の仕上げです
1人のsrcモデルが完成→女優さんの名前のフォルダとかに退避
モデル名を聞かれたら、女優さんの名前を入れています
2人目のsrcモデルは、まっさらから学習するより、1人のsrcを流用した方が完成が速い
モデルファイルを全部コピーして、女優A→女優Bにリネームしています
女優Bのsrcで学習します。最初少し女優Aの名残がありますが、学習するうちに女優Bになります
せっかく学習したsrcのモデルはコピーしてとっておきます
後で、別dstでやりたくなりますので
基本的に、eyes_prio: Falseです
どうしても視線が合わない物ができた時にTrueにしてもいいです
デフォルトでTrueにすると学習が遅くなりますし。Loss値が下がりません
liae-udでやっているので、モーフィングするので、視線がおかしくなる事はあまりありません
Enable gradient clipping yにすると、学習が遅くなります
nがおすすめです
nにしてもモデル崩壊はしません
kyouko_magica様
いつもありがとうございます。
助かります^^
今年の7月にでたバージョンを利用しており、フェイスタイプをfullで利用しており次はwholeに挑戦してみようと思いまして。6) train SAEHDの設定画面でフェイスタイプをfullからwholeに変更するにはどうしたらしたらいいんでしょうか?
ちなみにdstとsrcはそれ用に加工はしています。
一度fullでやったら変えれないんでしょうか?
質問です。
VR動画でも使えますか?
現在トレイン中なんですが、GPU使用率が2%程度、CPU使用率が35%程度になっているんですが、これは正常なんでしょうか?
Ryzen9 5950X
RTX3090
設定はGPUにしているはずなんですが、どうも使用率が低すぎる気がします。
ひょっとして、この組み合わせのパーツだと上手く起動しないんでしょうか?
https://github.com/iperov/DeepFaceLab
https://mrdeepfakes.com/forums/thread-1-1-sfw-guide-deepfacelab-2-0-guide-recommended-up-to-date
https://mrdeepfakes.com/forums/thread-3-1-sfw-guide-how-to-make-celebrity-datasets-guide
ダウンロード
https://mega.nz/folder/Po0nGQrA#dbbttiNWojCt8jzD4xYaPw
https://tinyurl.com/y4yct334
higutiさん
fullのモデルをバックアップ退避して
新しくゼロからwholeで6) train SAEHDするしか無いと思います
https://mrdeepfakes.com/forums/forum-trained-models
のモデルと設定が同じでよければ、モデル流用した方が完成が早いです
ksさん
使える様ですが、さすがにこの初心者向け一通り解説サイトで聞く事ではないかと
フォーラムや掲示板でしょうね
mrdeepfakes.com
mrdeepfakes.com/forums
オリジナル、本体
github.com/iperov/DeepFaceLab
ここのリンクに全てが
github.com/iperov/DeepFaceLab
mrdeepfakes.com/forums/thread-1-1-sfw-guide-deepfacelab-2-0-guide-recommended-up-to-date
mrdeepfakes.com/forums/thread-3-1-sfw-guide-how-to-make-celebrity-datasets-guide
ダウンロード
mega.nz/folder/Po0nGQrA#dbbttiNWojCt8jzD4xYaPw
/tinyurl.com/y4yct334
こんにちは。質問させていただきます。
顔部分の画像抽出を試みる際にGPUが認識されず、画像抽出ができていません。ドライバは最新のものをインストールしているのですが、何が原因なのでしょうか?
WF使ってみたいんですがWF用に加工というのがよくわからないです。WF用の加工というのはどういった加工なんでしょうか?またその加工というのは別途ソフトが必要でしょうか
質問失礼いたします。
マスクが途中途切れてしまうのですが、マスクの個別編集はどちらからやればいいでしょうか?
まあ、初心者向けに上手くできた一通り解説サイトはありますが
手取り足取り解説はしてはもらえませんな
質問全て試せる訳がない
質問に答えるためにやっている人はいない
無料ですし
くれぐれも勘違いなさらぬように
自分で色々と試してください
あとは掲示板に色々とあります
この1サイトで聞く話ではないですよ
このサイトの主さんは、あまり色々試していない方だと思いますけど
そんな事聞かれてもね
答えるにも情報が無さ過ぎですね
エスパーはいませんよ
質問できますが、答えの期待ができない物が多すぎの様な気がしますが
RTX3000用とそれ以前のグラボとで、ソフト2つに枝分かれしています
グラボはNVIDIAのみサポートです。CUDAとかその上の機械学習用のライブラリがあるのはNVIDIAのみ
人間の顔は眉、目、鼻、口、パーツのみです
おでこはパーツがありません。手動で、おでこの部分(髪無し)を定義、お絵かきするのでは?
debugの絵を見ると、各パーツのランドマーク(パーツの輪郭の目印)
顔と認識した範囲が分かります
srcもdstも顔抽出をWFで指定します
Xsegエディタで顔の部分、おでこを指定します。おでこを含め、顔のお絵描きします
髪は顔では無いです
Githubから辿れる、フォーラムのチュートリアル、FAQなどを見てください
英語ですが、ChromeのGoogle翻訳を使用して、十分に読めます
英語版を一切見ていないと、おかしな事になると思います
RCTとLCT、皆さんどっち選んでます?ずっとRCT選んでたけどLCTのほうが自然な気がしてきた。
RTX3000番台対応のdeepfacelabの解説を作る予定はありますか?
デバイスマネージャでNVIDIAのグラボが表示されていますか?
NVIDIAのグラボからディスプレイ表示とかできますか?
GAN powerの十分に訓練がされてから「 random warp of samples 」を無効にした上で、「y」(有効)にするオプションです。
とありますが、訓練した後にオプションを変える方法が知りたいです。
なぜここで聞くのでしょうか?
なぜ自分で試してみないのでしょうか?
なぜ正解をここで言ってもらえると思っているのでしょうか?
random warp of samples n
GAN power 数値を入れる
フォーラムに書いてあります
Google翻訳で十分読めます
ここは初心者向けなので、それ以上の事はGithubからのリンクを
DeepFacelabでGoogle検索の最初に出てきますが
作者は日本人ではありませんよ
英語圏で盛んです
世の中のみなさんは英語
ここは最新版への追従の話題もありませんけど
こちらのサイトにはDeepFaceLab1.0の時からお世話になっております…有り難うございます
今はある程度つくれるようになったのでdstをたくさん用意したり精度を上げられるように色々と試しています
Color transferについてですが
今までは『merge』の際にのみ各パラメーターを試して肌色が近いものを選んでいて
train時に関しては30時間ほどかけているので各モードを試せていません(いつもlct)
最近はsrcの顔がばっちりメイクに対してdstにはナチュラルが欲しくなっています
train時のColor transferでsrcのメイクの強弱(濃淡)を抑えられたりするものでしょうか?
もちろん素材によって最適な組み合わせはそれぞれだと思いますが
src(化粧濃いめ)
dst(化粧薄め)な際にtrain、merge時のColor transferお勧め設定はありますでしょうか?
特にtrain時にsrcの色変化が多かったりdstに比べ彩度が高い際に慣らしてくれるような
パラメーターがあれば教えていただけると助かります
(rct/lct/mkl/idt/sot)各調べましたが説明文をみても理解不能なのでお勧めがあればそれから試してみたいので…