
この記事ではDeepFaceLabで、学習する素材に静止画を使用する方法を紹介します。
DeepFaceLabを使って動画を制作するまでの一連の流れについては、こちらの記事で解説していますので、必要な方はこちらをご覧ください。
1.はじめに
今回は移植する顔となる「data_src」で、静止画を用いる方法を解説します。すでに分かっている方もいると思いますが、ここで少しおさらいしておきましょう。
data_src – 「別の人物の体に移植する顔となる素材」
data_dst – 「別の人物の顔を移植される素材」
例えば、映画ターミネーターの「アーノルド・シュワルツェネッガー」の顔に、「シルヴェスター・スタローン」顔を移植する場合、、 シルヴェスター・スタローンの素材が「data_src」、アーノルド・シュワルツェネッガーの素材が「data_dst」となります。
素材が写真・静止画だけは厳しい
基本的に高品質なdeepfakeを作るには、高品質かつ多くのパターンの画像が必要となります。対象となる人物の顔を様々な角度、方向から捉えた画像が必要ですし、その人物がまばたきをする一連の動作、表情の変化や口の動きなどが映っている素材などです。
このため、通常は顔が様々な角度から捉えられたもの、かつある程度長さのある動画を素材とします。(画像の枚数にして数千~数万枚)
そのなかで、品質向上のため動画から切り出した画像に、写真・静止画から切り出した画像を追加するということは有効かもしれません。しかし、静止画だけを素材とするのは厳しいと考えたほうがいいでしょう。
あくまで、写真・静止画は動画素材 + αと考えてもらうのが良いと思います。
2.使用する写真・静止画の注意点
動画素材と同様に使用する素材にいくつか注意点があります。
・画像に複数の人物の顔が映っていないこと
集めた画像から、人物の顔部分のみを画像で書き出すわけですが、画像内のすべての人物の顔が書き出されますので、画像には素材にしたい人物の顔のみが写っているようにしましょう。
他の人物の顔が写っている場合は、事前にトリミングしておく、顔と認識されないよう、単色で塗りつぶす、モザイクをかける等の処理をしておくことをおすすめします。後から、削除するのでも問題ないですが、大量の顔画像の中から探すのは大変面倒です。
・人物の顔が十分なサイズで写っていること
素材となる画像には人物の顔がある程度の大きく映っている必要があります。具体的には顔部分の画像の書き出しサイズは256×256ピクセルの正方形なので、動画上の人物の顔のサイズがこの程度のサイズで写っていることが望ましいでしょう。(現時点でtrain時の解像度は最大でも128×128ピクセルなので、この程度でも良いかもしれません)
画像にいくら顔が大きく映っていても、 書き出しは256×256ピクセルの正方形 ですから、元画像が6000 × 4000 ピクセルとかあっても特に良いことはありません。
3.写真・静止画から顔部分のみを書き出す
さて、本題の写真・静止画を素材として利用する方法紹介していきます。
これは必須ではないですが、DeepFaceLabのフォルダを丸々コピーして作業用のものを作ります。実際に学習(train)するフォルダとは、分けておいたほうが便利かなと思います。場所はデスクトップでも、Cドライブ直下でも、どこでも構いません。
次に、「workspace/data_src」内に、使いたい画像をすべて入れます。今回は解説のためロイヤリティフリーの写真素材を使っています。
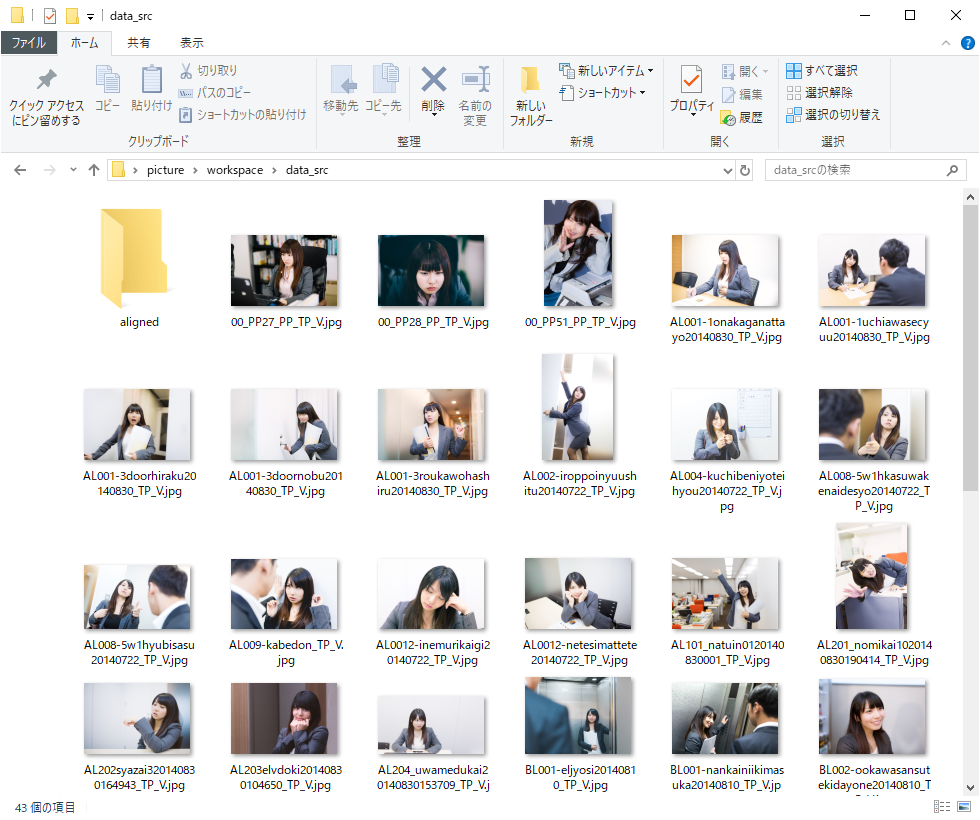
「aligned」のフォルダはあってもなくても、構いません。次にbatを実行するときに 「aligned」 フォルダがなければ自動的に作られます。
また、画像の名前も連番等にする必要はなく、そのままで大丈夫です。
顔部分の画像のみを書き出す
「workspase」フォルダ内にある「4) data_src extract faces S3FD best GPU.bat」を実行します。
batファイルを実行すると、ウィンドウが立ち上がり、こんな感じになります。batファイルを実行してから、動作するまで少し時間がかかる場合もあるので、その時は少し待ちましょう。
だいぶ待っても始まらない場合は、「×」でウィンドウを閉じて、再度batファイルを実行してみてください。
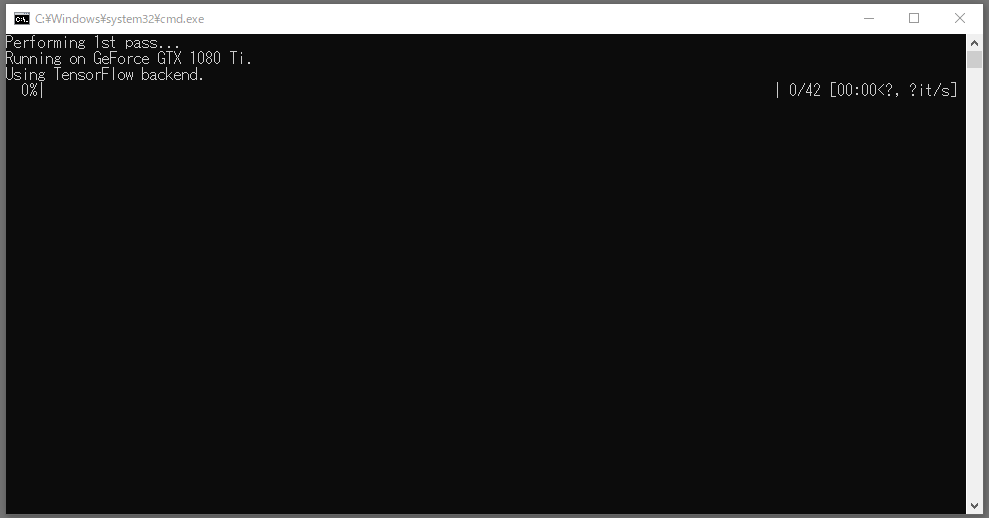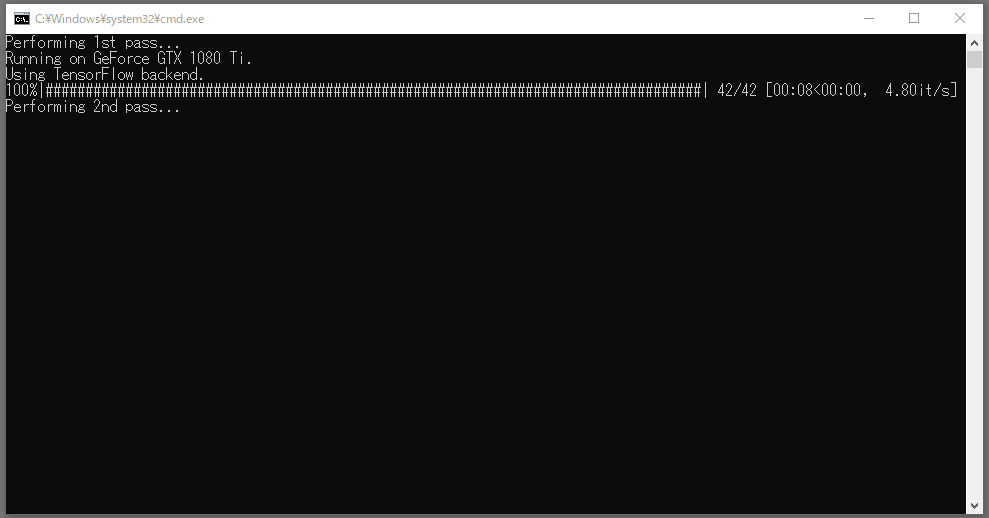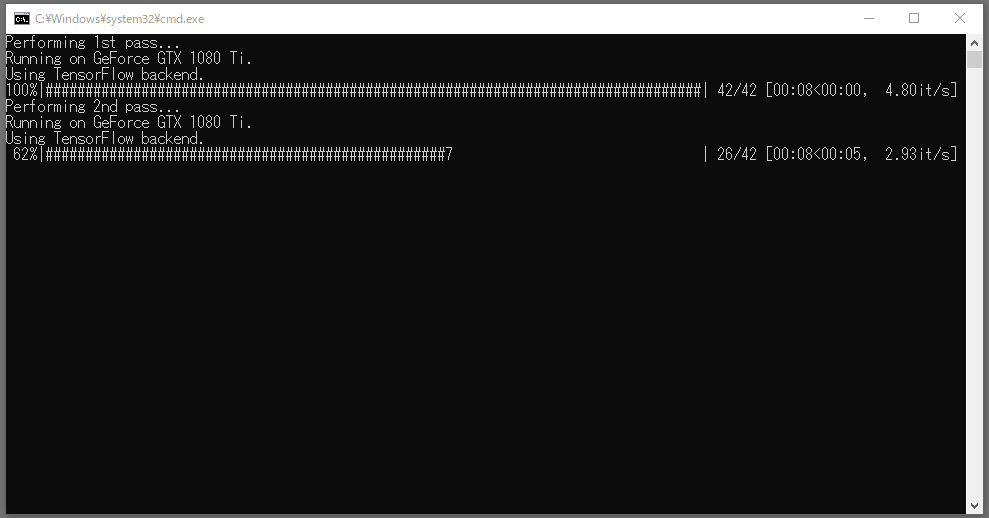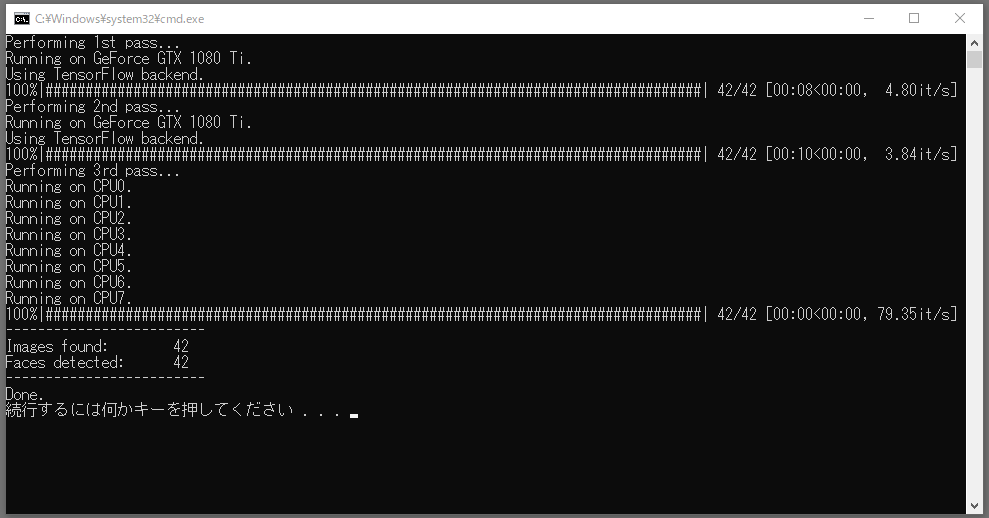
画像の書き出しが終わったら「workspace/data_src/aligned」フォルダ内に顔部分の画像が書き出されているか、確認しましょう。
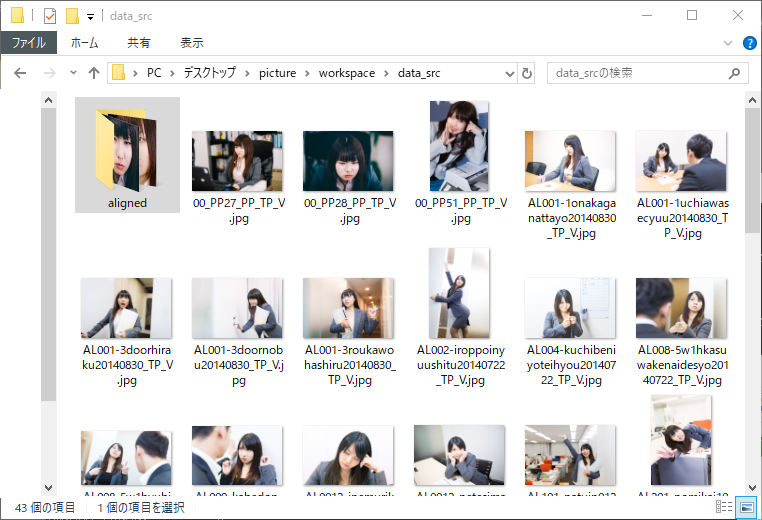
顔部分の画像のみが書き出された「workspace/data_src/aligned」 フォルダ内。もしも顔じゃない画像が、誤検出で書き出されていた場合は削除してください。
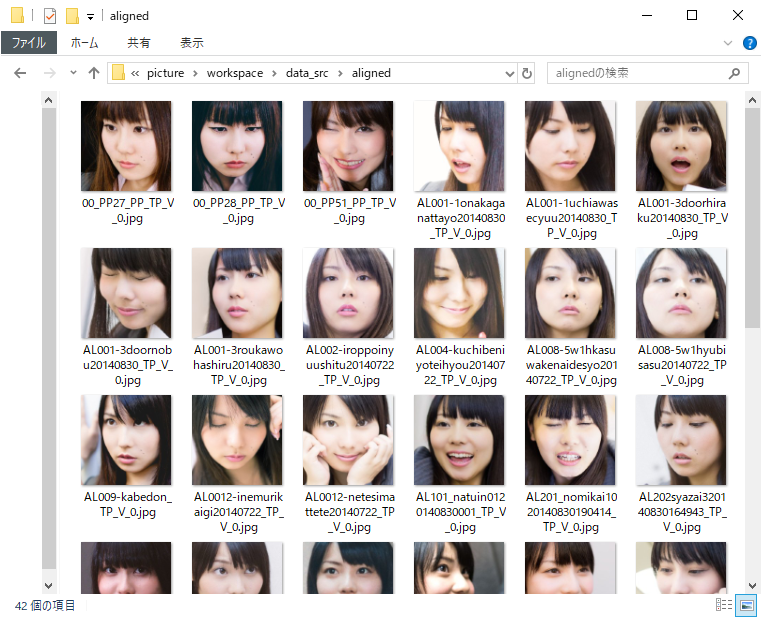
書き出した、alignedフォルダ内の画像は、実際に学習(train)させるDeepFaceLabのフォルダの「workspace/data_src/aligned」にコピーまたは移動させて、動画から書き出した素材と混ぜて学習(train)させてください。


こんにちわ 教えて欲しいのですが
core i7 3770 gtx960 4gbを使用してます。
このスペックのせいなのか わかりませんが trin Quick96 なら普通にスグ動くのですが、tain SAEHD にすると全然先へ進まないのはスペック不足なのでしょうか?
それと data_dst merged の顔の画像が ドス黒く絵で描いたような感じになるのですが何故なのでしょうか?
その前の aligned_debug の顔が赤と青の四角の枠で囲まれて青い枠の中の顔を含む
部分が黒くなってるのは普通なのでしょうか?
よろしくお願い致します。
素材からの顔データの抽出は「動画」から行っておいて、実際の入力&出力は「静止画」で行うことはできますか?